
Supervised Learning là gì? Cách AI dự đoán kết quả chính xác
28/05/2026Ngày nay, gần như mọi nền tảng lớn đều đang sử dụng Machine Learning (máy học) để xử lý dữ liệu và tự động đưa ra dự đoán. Một trong những nền tảng quan trọng nhất phía sau sự phát triển đó là Supervised Learning (học có giám sát).
Đây là phương pháp giúp AI “học từ đáp án đúng”, tương tự cách con người học thông qua ví dụ và hướng dẫn. Hầu hết các hệ thống AI hiện đại như nhận diện khuôn mặt, lọc spam email, đề xuất nội dung hay dự đoán hành vi khách hàng đều được xây dựng dựa trên mô hình này.
Supervised Learning là gì?
Supervised Learning là phương pháp huấn luyện AI bằng dữ liệu đã được gắn nhãn (labeled data). Mỗi dữ liệu đầu vào đều có sẵn “đáp án đúng” để AI học cách dự đoán kết quả chính xác hơn theo thời gian.
Ví dụ, nếu muốn huấn luyện AI nhận diện mèo và chó, hệ thống sẽ được cung cấp hàng triệu hình ảnh đã có nhãn “mèo” hoặc “chó”. AI sau đó học cách nhận ra đặc điểm của từng nhóm dữ liệu để đưa ra dự đoán khi gặp dữ liệu mới.
Quá trình training thường diễn ra liên tục theo vòng lặp. AI nhận dữ liệu đầu vào, đưa ra dự đoán, so sánh với đáp án thật rồi tự điều chỉnh thuật toán để giảm sai số. Sau hàng triệu lần lặp, mô hình sẽ ngày càng chính xác hơn.
Theo IBM, Supervised Learning hiện là một trong những kỹ thuật Machine Learning phổ biến nhất nhờ khả năng dự đoán chính xác và dễ ứng dụng trong doanh nghiệp.
>>> Xem thêm Machine Learning là gì?
AI học như thế nào trong Supervised Learning?
Có thể hình dung Supervised Learning giống cách giáo viên dạy học sinh bằng ví dụ thực tế. Ví dụ, giáo viên liên tục cho học sinh xem ảnh quả táo và nói “đây là táo”. Sau hàng nghìn lần lặp với nhiều hình ảnh khác nhau, học sinh dần hiểu được đặc điểm chung của quả táo như màu sắc, hình dạng hay texture bề mặt.
AI cũng hoạt động tương tự. Thay vì “ghi nhớ” từng bức ảnh riêng lẻ, mô hình sẽ cố gắng tìm ra pattern (mẫu dữ liệu) để nhận diện chính xác khi gặp dữ liệu mới chưa từng xuất hiện trước đó.
Điểm quan trọng nhất của Supervised Learning nằm ở chất lượng dữ liệu. Nếu dữ liệu sai, thiếu hoặc bị lệch, AI cũng sẽ học sai. Đây là lý do các công ty công nghệ lớn hiện đầu tư rất mạnh vào việc thu thập, làm sạch và gắn nhãn dữ liệu AI.
Dữ liệu gắn nhãn quan trọng như thế nào?
Trong Supervised Learning, dữ liệu gắn nhãn gần như quyết định chất lượng của AI. Nếu dữ liệu sai nhãn, thiếu đa dạng, thiên lệch hoặc là quá ít thì mô hình sẽ dự đoán kém dù thuật toán mạnh đến đâu.
Nếu AI nhận diện khuôn mặt chỉ được train bằng dữ liệu của một nhóm người nhất định, hệ thống có thể hoạt động thiếu chính xác với những nhóm dữ liệu khác. Theo MIT Technology Review, chất lượng dữ liệu hiện là một trong những yếu tố ảnh hưởng lớn nhất tới hiệu suất AI hiện đại.
Hai dạng bài toán chính của Supervised Learning
Classification (phân loại)
Classification là dạng bài toán dùng để dự đoán nhãn hoặc nhóm dữ liệu. Đây là loại phổ biến nhất trong Supervised Learning.
Ví dụ, AI có thể xác định email là spam hay không spam, nhận diện khuôn mặt, phân tích bình luận tích cực hay tiêu cực hoặc phát hiện giao dịch gian lận trong ngân hàng.
Các hệ thống AI camera, Face Recognition hay chatbot moderation hiện nay đều hoạt động dựa trên classification.
Những thuật toán thường được sử dụng cho classification gồm Logistic Regression, Decision Tree, Random Forest, Support Vector Machine và Neural Network.
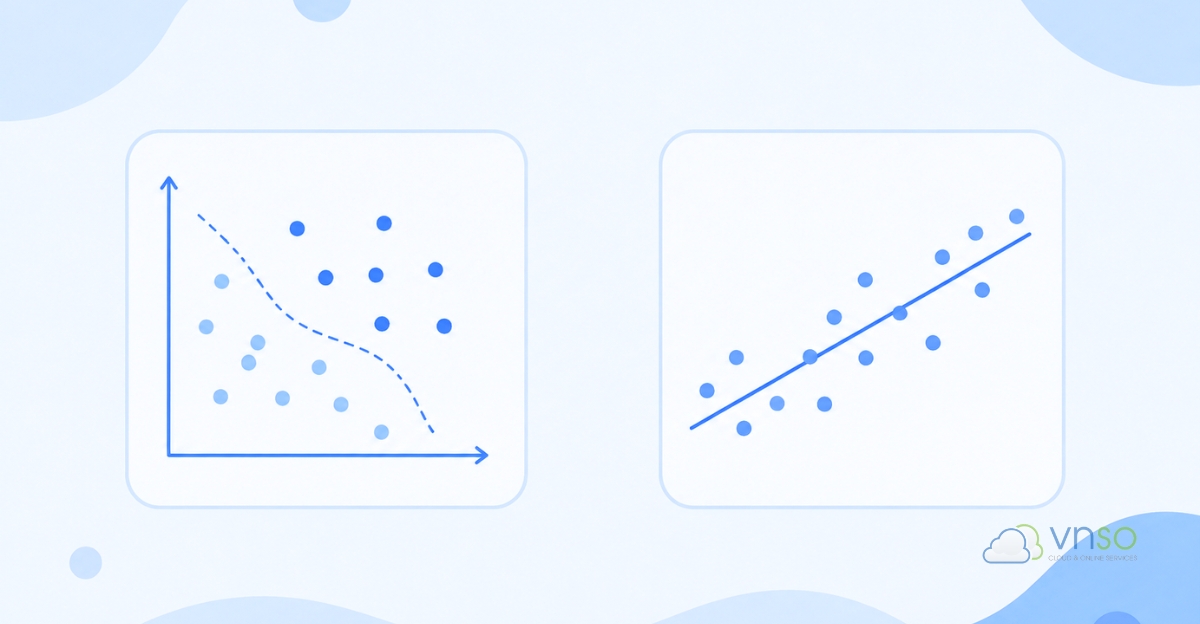
Regression (hồi quy)
Regression dùng để dự đoán giá trị số thay vì phân loại dữ liệu thành từng nhóm. Ví dụ, AI có thể dự đoán giá nhà, doanh thu tháng sau, nhu cầu mua hàng hoặc tỷ lệ chuyển đổi marketing. Khác với classification, regression thường được sử dụng khi doanh nghiệp cần phân tích xu hướng hoặc dự báo dữ liệu trong tương lai.
Thay vì trả lời “có” hoặc “không”, AI sẽ đưa ra kết quả như:
– Giá căn hộ dự đoán khoảng 3,2 tỷ VNĐ
– Doanh thu tháng tới khoảng 1,4 tỷ VNĐ
Các thuật toán Supervised Learning phổ biến
Linear Regression
Linear Regression là một trong những mô hình Machine Learning cơ bản nhất. Thuật toán này tìm mối quan hệ giữa dữ liệu đầu vào và kết quả đầu ra.
Ví dụ, AI có thể học rằng diện tích nhà càng lớn thì giá bán thường càng cao.
Ưu điểm của Linear Regression nằm ở khả năng triển khai đơn giản, tốc độ xử lý nhanh và dễ giải thích. Tuy nhiên, mô hình này khó xử lý các bài toán dữ liệu phức tạp hoặc phi tuyến tính.
Logistic Regression
Dù có tên “Regression”, thuật toán này chủ yếu được sử dụng cho phân loại dữ liệu.
Ví dụ, AI có thể dự đoán khách hàng có mua hàng hay không hoặc người dùng có nhấn vào quảng cáo hay không.
Logistic Regression hiện vẫn được sử dụng rất nhiều trong marketing automation, phân tích CRM và fintech nhờ khả năng triển khai nhanh và chi phí tính toán thấp.
Decision Tree
Decision Tree hoạt động giống sơ đồ quyết định dạng cây.
AI sẽ liên tục đặt câu hỏi như:
- Tuổi khách hàng có trên 30 không?
- Thu nhập có vượt mức X không?
- Người dùng từng mua sản phẩm chưa?
Từ đó, hệ thống đưa ra quyết định cuối cùng. Ưu điểm của Decision Tree là trực quan, dễ visualize và dễ giải thích với doanh nghiệp. Tuy nhiên, thuật toán này dễ gặp hiện tượng overfitting nếu dữ liệu training không đủ đa dạng.

Random Forest
Random Forest là phiên bản nâng cấp của Decision Tree.
Thay vì chỉ dùng một cây quyết định, hệ thống sẽ kết hợp nhiều cây khác nhau rồi lấy kết quả tổng hợp. Cách làm này giúp AI ổn định hơn và giảm nguy cơ dự đoán sai.
Random Forest hiện được sử dụng rất nhiều trong ngân hàng, AI tài chính và hệ thống chấm điểm tín dụng vì độ chính xác cao và khả năng xử lý dữ liệu lớn tốt hơn Decision Tree thông thường.
Neural Network
Neural Network là nền tảng cốt lõi của Deep Learning (học sâu).
Đây là công nghệ đứng sau nhiều hệ thống AI hiện đại như ChatGPT, AI tạo ảnh, AI voice, xe tự lái hay AI dịch thuật.
Khác với thuật toán truyền thống, Neural Network có thể học những pattern cực kỳ phức tạp từ dữ liệu lớn. Đây cũng là lý do Deep Learning đang trở thành xu hướng trung tâm của ngành AI toàn cầu.
>>> Xem thêm Neural Network là gì? Khám phá Mạng Nơ-ron nhân tạo từ A-Z
Overfitting, điểm hạn chế của Supervised Learning
Overfitting (quá khớp) là vấn đề cực kỳ phổ biến trong Machine Learning. Hiện tượng này xảy ra khi AI học quá kỹ dữ liệu training tới mức “ghi nhớ đáp án” thay vì hiểu quy luật tổng quát. Kết quả là mô hình có thể đạt điểm rất cao trong lúc train nhưng hoạt động kém khi gặp dữ liệu thực tế.
Ví dụ, AI có thể nhận diện chính xác những hình ảnh từng xuất hiện trong dataset nhưng lại thất bại với ảnh mới ngoài đời thực. Để hạn chế overfitting, các kỹ thuật như validation, regularization và tăng đa dạng dữ liệu thường được sử dụng trong quá trình huấn luyện.
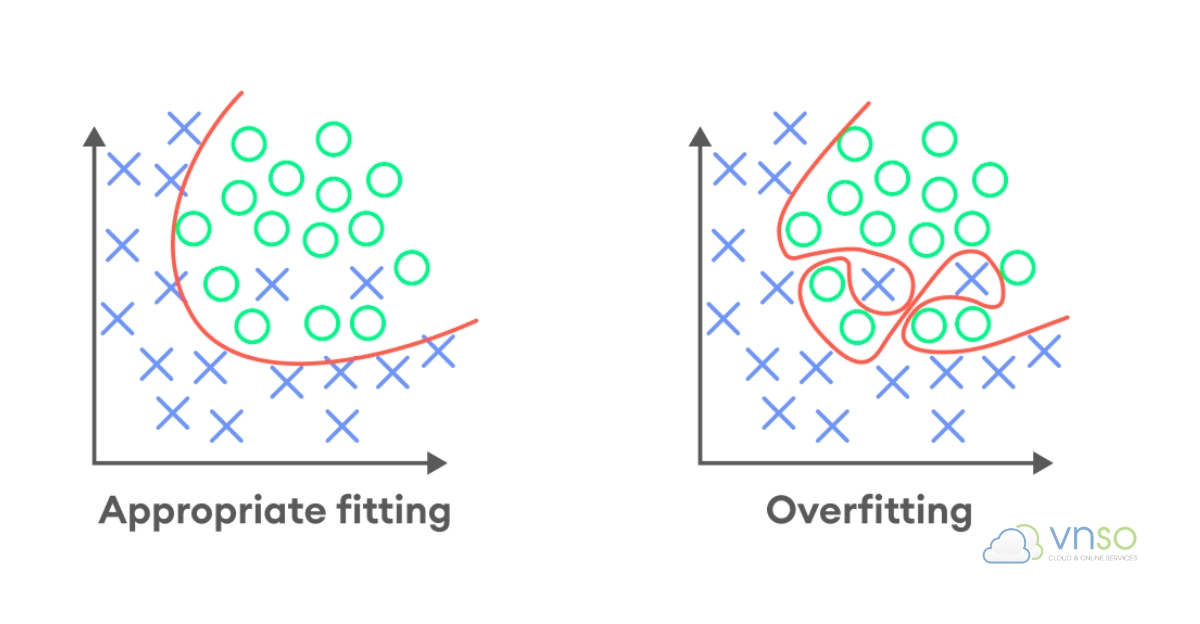
Overfitting (Quá khớp) trong Supervised Learning (Học có giám sát)
So sánh Supervised Learning vs Unsupervised Learning
Điểm khác biệt lớn nhất giữa hai phương pháp nằm ở dữ liệu. Supervised Learning sử dụng dữ liệu có nhãn và có sẵn đáp án đúng để AI học cách dự đoán.
Trong khi đó, Unsupervised Learning (học không giám sát) dùng dữ liệu chưa gắn nhãn. AI sẽ tự tìm pattern hoặc tự nhóm dữ liệu dựa trên đặc điểm chung.
Ví dụ:
– Supervised Learning thường dùng để dự đoán khách hàng có mua hàng hay không
– Unsupervised Learning thường dùng để phân nhóm khách hàng theo hành vi tiêu dùng
Supervised Learning thường cho độ chính xác cao hơn nhưng cũng tốn nhiều chi phí dữ liệu hơn.
>>> Xem thêm Unsupervised Learning là gì? Cách AI tự học phân tích dữ liệu
Supervised Learning được ứng dụng ở đâu?
Supervised Learning hiện xuất hiện trong gần như mọi ngành công nghệ hiện đại.
Trong tài chính, AI được dùng để phát hiện gian lận giao dịch, chấm điểm tín dụng và dự đoán rủi ro.
Trong thương mại điện tử, các nền tảng như Shopee, Amazon hay TikTok Shop sử dụng AI để gợi ý sản phẩm, cá nhân hóa quảng cáo và dự đoán hành vi mua hàng.
Trong Computer Vision (thị giác máy tính), Supervised Learning giúp AI nhận diện khuôn mặt, xử lý OCR, phân tích hình ảnh y tế và hỗ trợ camera AI.
Ngành cybersecurity (An ninh mạng) cũng đang ứng dụng mạnh Supervised Learning để phát hiện malware, chặn spam và nhận diện hành vi bất thường theo thời gian thực.
>>> Xem thêm Tại sao các sàn thương mại điện tử cần Dedicated Server mùa săn sale?

Xu hướng Supervised Learning năm 2026
Theo Statista, Nền tảng này tổng hợp số liệu thống kê, báo cáo và khảo sát thị trường từ hơn 22.500 nguồn uy tín trên toàn thế giới, bao gồm hàng trăm quốc gia, thị trường AI toàn cầu dự kiến có thể vượt 826 tỷ USD vào năm 2030, trong đó Machine Learning là một trong những công nghệ phát triển nhanh nhất.
Supervised Learning hiện đang bước vào giai đoạn tăng trưởng rất mạnh nhờ sự bùng nổ của AI tạo sinh và Large Language Model (LLM).
Các công ty công nghệ hiện không còn chỉ train AI cho chatbot mà còn mở rộng sang:
– AI video
– AI voice
– Coding bằng AI
– AI agent
– AI tìm kiếm
Một xu hướng đáng chú ý khác là Synthetic Data, tức sử dụng AI để tự tạo dữ liệu huấn luyện thay vì gắn nhãn thủ công. Gartner dự báo tới năm 2030, phần lớn dữ liệu dùng cho AI có thể là synthetic data thay vì dữ liệu thực.
Ngoài ra, AutoML cũng đang phát triển nhanh. Công nghệ này cho phép tự động chọn model, tối ưu tham số và triển khai AI mà không cần quá nhiều chuyên môn Machine Learning.
Kết luận
Supervised Learning là nền tảng cốt lõi của AI hiện đại. Phần lớn ứng dụng AI ngày nay đều đang hoạt động dựa trên dữ liệu gắn nhãn và quá trình huấn luyện có giám sát.
Khi AI tiếp tục phát triển mạnh trong nhiều lĩnh vực khác nhau, Supervised Learning vẫn sẽ đóng vai trò trung tâm nhờ khả năng dự đoán chính xác và tính ứng dụng cực cao trong thực tế.
Cách triển khai máy học, Supervised learning hiệu quả nhất tại Việt Nam
Khi triển khai Supervised Learning thực tế, nhiều doanh nghiệp Việt thường gặp khó khăn vì chi phí đầu tư GPU AI rất cao. Một card NVIDIA A100 có thể trị giá hàng chục nghìn USD, chưa tính server, điện năng và vận hành hệ thống. Đây là lý do mô hình Cloud GPU đang trở thành lựa chọn phổ biến cho AI startup, developer và doanh nghiệp triển khai Machine Learning.
Tại VNSO, người dùng có thể thuê Cloud GPU NVIDIA A100 chỉ từ 59.000 VNĐ/giờ với thời gian khởi tạo trong vòng 5 phút, hỗ trợ sẵn môi trường AI như CUDA, PyTorch, TensorFlow và kho model AI preloaded như LLaMA, Mistral hay Stable Diffusion để rút ngắn thời gian triển khai thực tế. Ngoài Cloud GPU, VNSO cũng cung cấp Server GPU chuyên dụng dành cho doanh nghiệp cần training AI, fine-tuning LLM hoặc inference production quy mô lớn
>>> Điền thông tin để nhận tư vấn từ chuyên gia VNSO, giải đáp mọi thắc mắc của bạn miễn phí.
Các câu hỏi thường gặp về Supervised Learning (FAQ)
Supervised Learning có cần biết lập trình không?
Có, nhưng mức độ phụ thuộc vào mục tiêu sử dụng. Nếu chỉ học kiến thức cơ bản, người dùng có thể bắt đầu với các công cụ AutoML hoặc nền tảng AI trực quan mà không cần viết quá nhiều code. Tuy nhiên, để xây dựng mô hình AI thực tế, tối ưu thuật toán hoặc training dữ liệu lớn, kiến thức Python, Machine Learning framework và xử lý dữ liệu vẫn rất quan trọng.
Supervised Learning có phải là AI không?
Supervised Learning là một nhánh của Machine Learning, còn Machine Learning là một phần của AI (trí tuệ nhân tạo). Có thể hiểu đơn giản, đây là phương pháp giúp AI học từ dữ liệu để tự đưa ra dự đoán hoặc quyết định.
Supervised Learning có dùng được cho dữ liệu thời gian thực không?
Có. Nhiều hệ thống AI hiện nay đang sử dụng Supervised Learning để xử lý dữ liệu theo thời gian thực như phát hiện gian lận ngân hàng, lọc spam email, đề xuất video hoặc nhận diện hành vi bất thường trên hệ thống bảo mật.
Fine-tuning AI có liên quan tới Supervised Learning không?
Có. Fine-tuning thường sử dụng dữ liệu đã gắn nhãn để tiếp tục huấn luyện mô hình AI có sẵn nhằm tối ưu cho một tác vụ cụ thể. Đây là phương pháp phổ biến khi doanh nghiệp muốn tùy chỉnh LLM, chatbot AI hoặc AI nội bộ theo dữ liệu riêng.
Dataset càng lớn thì AI có càng chính xác không?
Không phải lúc nào cũng vậy. Dataset lớn giúp AI học được nhiều pattern hơn, nhưng nếu dữ liệu kém chất lượng hoặc bị trùng lặp quá nhiều thì hiệu quả training vẫn có thể thấp. Trong nhiều trường hợp, dữ liệu sạch và đa dạng quan trọng hơn số lượng đơn thuần.
Supervised Learning có thể tự học hoàn toàn không?
Không hoàn toàn. Mô hình vẫn cần con người chuẩn bị dữ liệu, gắn nhãn, kiểm tra kết quả và tối ưu quá trình training. AI hiện nay rất mạnh trong việc học pattern, nhưng vẫn phụ thuộc lớn vào dữ liệu và mục tiêu do con người thiết lập.
Supervised Learning có phù hợp với doanh nghiệp nhỏ không?
Có. Hiện nay doanh nghiệp nhỏ vẫn có thể triển khai AI nhờ mô hình Cloud GPU và AI-as-a-Service thay vì phải đầu tư hạ tầng GPU hàng tỷ đồng. Điều này giúp startup và SME dễ tiếp cận Machine Learning hơn trước rất nhiều.
Supervised Learning có thay thế con người không?
Công nghệ này chủ yếu hỗ trợ tự động hóa và tăng tốc xử lý dữ liệu. Trong thực tế, Supervised Learning thường giúp giảm khối lượng công việc lặp lại thay vì thay thế hoàn toàn con người. Những quyết định quan trọng vẫn cần con người kiểm tra và đánh giá.
Mất bao lâu để train một mô hình Supervised Learning?
Thời gian training phụ thuộc vào kích thước dataset, độ phức tạp của mô hình và sức mạnh phần cứng. Một mô hình nhỏ có thể train trong vài phút hoặc vài giờ, trong khi các hệ thống AI lớn có thể mất nhiều ngày hoặc nhiều tuần để hoàn thành.
Supervised Learning có thể dùng cho tiếng Việt không?
Có. Hiện nay nhiều mô hình AI đã hỗ trợ xử lý tiếng Việt khá tốt trong các tác vụ như chatbot, phân tích cảm xúc, OCR hay tìm kiếm thông minh. Tuy nhiên, hiệu quả vẫn phụ thuộc vào chất lượng dataset tiếng Việt được sử dụng để huấn luyện.
Thông tin liên hệ
Để tìm hiểu thông tin về các giải pháp AI, Máy chủ, và Điện toán đám mây… Quý khách vui lòng liên hệ chúng tôi theo thông tin dưới đây:
CÔNG TY CỔ PHẦN CÔNG NGHỆ VNSO – SINCE 2015
– Website: https://vnso.vn/
– Fanpage: Facebook | LinkedIn | YouTube | TikTok
– Hotline: 0927 444 222 | Email: info@vnso.vn
– Trụ sở: Lô O số 10, Đường số 15, KDC Miếu Nổi, Phường Gia Định, TP. Hồ Chí Minh
– VPGD Đà Nẵng: 30 Nguyễn Hữu Thọ, Phường Hải Châu, Đà Nẵng
– VPGD Hà Nội: 132 Vũ Phạm Hàm, Phường Yên Hòa, Hà Nội










