
Semi-Supervised Learning là gì? Tìm hiểu học bán giám sát từ A-Z
29/05/2026Semi-Supervised Learning (học bán giám sát) trở thành một trong những hướng phát triển quan trọng nhất của Machine Learning (máy học). Công nghệ này cho phép AI học hiệu quả ngay cả khi chỉ có một lượng nhỏ dữ liệu được con người phân loại sẵn.
Trong nhiều hệ thống AI hiện đại, Semi-Supervised Learning đang giúp giảm mạnh chi phí xử lý dữ liệu, rút ngắn thời gian huấn luyện và cải thiện độ chính xác của mô hình.
Semi-Supervised Learning là gì?
Semi-Supervised Learning là phương pháp huấn luyện AI kết hợp giữa dữ liệu có nhãn và dữ liệu chưa gắn nhãn. Thay vì phụ thuộc hoàn toàn vào dữ liệu đã được con người phân loại trước, mô hình AI có thể tận dụng thêm lượng dữ liệu khổng lồ chưa được xử lý để tiếp tục học và cải thiện kết quả.
Trong Machine Learning truyền thống, AI thường cần lượng lớn dữ liệu được gắn nhãn đầy đủ. Ví dụ, nếu muốn huấn luyện AI nhận diện xe ô tô và xe máy, hàng chục nghìn bức ảnh phải được đánh dấu rõ đâu là xe ô tô và đâu là xe máy trước khi đưa vào huấn luyện (training).

Theo Google Research (bộ phận nghiên cứu AI của Google), việc gắn nhãn dữ liệu cho các mô hình AI lớn có thể tiêu tốn hàng nghìn giờ lao động thủ công. Trong những lĩnh vực như y tế hoặc xe tự lái, dữ liệu còn cần chuyên gia đánh giá nên chi phí tăng cao hơn rất nhiều.
Semi-Supervised Learning giải quyết vấn đề này bằng cách để AI học từ một lượng nhỏ dữ liệu đã gắn nhãn, sau đó tận dụng lượng lớn dữ liệu chưa được phân loại để mở rộng khả năng học. Ví dụ, thay vì cần 100.000 ảnh được gắn nhãn, mô hình có thể chỉ cần vài nghìn ảnh đã phân loại trước rồi tự học thêm từ hàng trăm nghìn ảnh còn lại. Cách tiếp cận này giúp tiết kiệm đáng kể tài nguyên và mở rộng khả năng huấn luyện AI trên quy mô lớn.
>>> Xem thêm Machine Learning là gì? Tìm hiểu A-Z và cách triển khai máy học
Vì sao Semi-Supervised Learning trở nên quan trọng?
Trong thực tế, dữ liệu chưa gắn nhãn luôn nhiều hơn dữ liệu có nhãn. Mỗi phút có hơn 500 giờ video được tải lên YouTube theo YouTube Official Blog. Phần lớn video này không có mô tả chi tiết hoặc nhãn đầy đủ để AI hiểu toàn bộ nội dung.
Tương tự, các bệnh viện có thể lưu trữ hàng triệu ảnh X-quang nhưng chỉ một phần nhỏ được bác sĩ chú thích đầy đủ. Với Semi-Supervised Learning, AI có thể tận dụng khối dữ liệu khổng lồ này để cải thiện khả năng nhận diện bệnh.
IBM Research cho biết hơn 80% dữ liệu doanh nghiệp hiện nay là dữ liệu phi cấu trúc, bao gồm hình ảnh, video và văn bản chưa được phân loại đầy đủ. Điều này khiến Semi-Supervised Learning trở thành lựa chọn phù hợp cho nhiều hệ thống AI hiện đại.
Khi dữ liệu toàn cầu tiếp tục tăng nhanh, việc phụ thuộc hoàn toàn vào dữ liệu gắn nhãn thủ công ngày càng trở nên tốn kém. Semi-Supervised Learning giúp doanh nghiệp tận dụng dữ liệu sẵn có hiệu quả hơn mà không cần tăng quá nhiều chi phí xử lý.
Semi-Supervised Learning hoạt động như thế nào?
Quá trình hoạt động của Semi-Supervised Learning thường bắt đầu bằng việc AI học từ lượng dữ liệu đã được gắn nhãn. Đây là bước giúp mô hình hiểu những đặc điểm cơ bản của dữ liệu.
Sau khi có nền tảng ban đầu, AI sẽ bắt đầu dự đoán nhãn cho dữ liệu chưa được phân loại. Ví dụ, nếu mô hình đã học được đặc điểm của mèo từ 1.000 ảnh có nhãn, nó có thể tự suy đoán hàng chục nghìn ảnh khác nhiều khả năng cũng là mèo.
Những dự đoán có độ tin cậy cao sẽ được giữ lại như “pseudo labels” hay nhãn tạm thời. Sau đó, AI tiếp tục huấn luyện lại chính mình dựa trên tập dữ liệu mở rộng này. Quá trình lặp lại liên tục giúp mô hình ngày càng cải thiện độ chính xác.
Đây là lý do Semi-Supervised Learning thường được xem là bước trung gian giữa Supervised Learning (học có giám sát) và Unsupervised Learning (học không giám sát).
Pseudo Labeling – AI tự tạo nhãn cho dữ liệu chưa được gắn nhãn
Pseudo Labeling là một trong những kỹ thuật nổi tiếng nhất của Semi-Supervised Learning. Với phương pháp này, AI sẽ tự tạo nhãn cho dữ liệu chưa được gắn nhãn dựa trên dự đoán của chính nó.
Ví dụ, AI nhìn một bức ảnh và dự đoán 98% khả năng đó là chó. Hệ thống sẽ tạm xem ảnh này là “chó” và tiếp tục sử dụng nó để huấn luyện mô hình.
Theo Papers With Code (nền tảng tổng hợp benchmark AI nổi tiếng), Pseudo Labeling xuất hiện trong rất nhiều nghiên cứu AI hiện đại nhờ khả năng tận dụng dữ liệu lớn với chi phí thấp.
Kỹ thuật này đặc biệt hữu ích trong các hệ thống Computer Vision (thị giác máy tính), nơi lượng dữ liệu hình ảnh thường cực kỳ lớn.
Consistency Regularization giúp cải thiện đáng kể độ chính xác
Một kỹ thuật quan trọng khác trong Semi-Supervised Learning là Consistency Regularization. Ý tưởng của phương pháp này khá đơn giản: nếu cùng một bức ảnh bị xoay nhẹ, làm mờ hoặc thay đổi ánh sáng, AI vẫn phải đưa ra kết quả giống nhau.
Ví dụ, một bức ảnh mèo bị xoay 10 độ hoặc tăng giảm độ sáng thì AI vẫn cần nhận diện đúng đó là mèo. Điều này giúp mô hình ổn định hơn và tăng khả năng tổng quát hóa dữ liệu.
Nhiều nghiên cứu từ Google AI Blog cho thấy kỹ thuật này giúp cải thiện đáng kể độ chính xác trong các mô hình Computer Vision hiện đại.
Các thuật toán Semi-Supervised Learning nổi bật
Trong vài năm gần đây, nhiều thuật toán Semi-Supervised Learning đã trở thành tiêu chuẩn trong nghiên cứu AI. Một trong những thuật toán nổi bật nhất là FixMatch do Google Research phát triển. Theo công bố trên arXiv, FixMatch đạt độ chính xác rất cao trên CIFAR-10 dù chỉ sử dụng một phần nhỏ dữ liệu có nhãn.
MixMatch cũng là kỹ thuật được sử dụng rộng rãi trong Deep Learning (học sâu). Thuật toán này kết hợp pseudo labeling với data augmentation nhằm cải thiện khả năng học từ dữ liệu chưa gắn nhãn.
Một thuật toán khác là Mean Teacher, hoạt động theo mô hình “teacher-student”, nơi một AI đóng vai trò hướng dẫn cho AI khác trong quá trình huấn luyện.
Ngoài ra còn có nhiều kỹ thuật nổi bật khác như VAT (Virtual Adversarial Training), Self-Training, Graph-Based SSL và Co-Training. Những phương pháp này hiện xuất hiện ngày càng nhiều trong các nghiên cứu về Computer Vision, NLP và Generative AI.
>>> Xem thêm Train Model AI là gì? Tất cả những gì bạn cần biết về huấn luyện AI
Semi-Supervised Learning khác gì Supervised Learning và Unsupervised Learning?
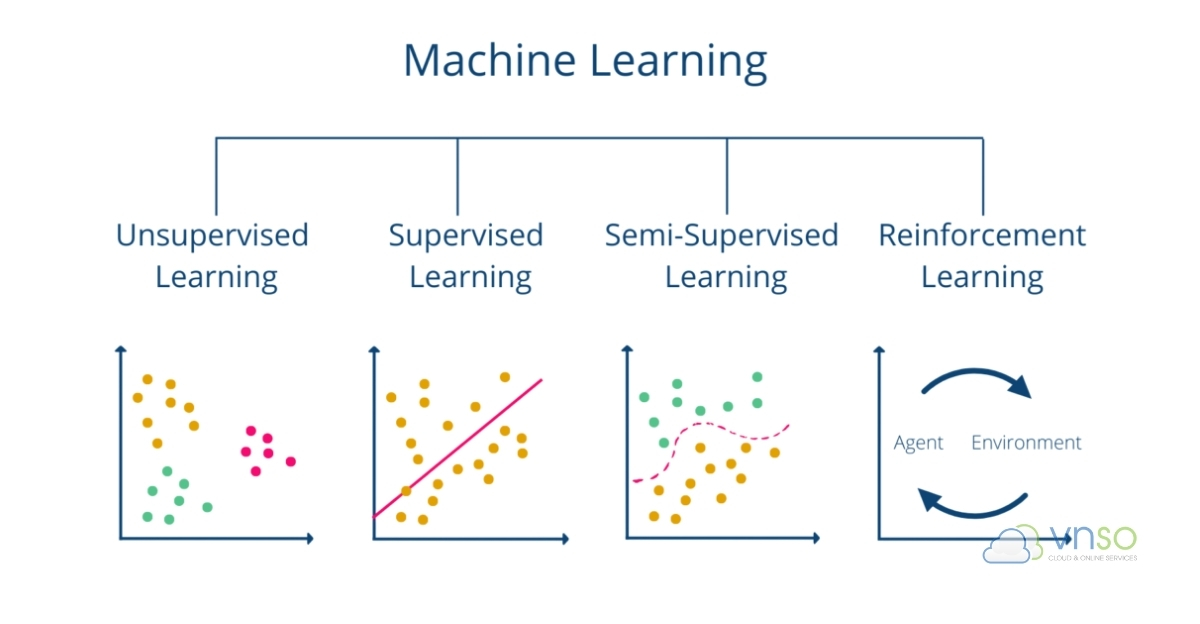
Các loại Machine Learning phổ biến
Dù đều thuộc nhóm Machine Learning (máy học), Semi-Supervised Learning, Unsupervised Learning (học không giám sát) và Supervised Learning (học có giám sát) có cách xử lý dữ liệu hoàn toàn khác nhau.
| Tiêu chí | Supervised Learning | Semi-Supervised Learning | Unsupervised Learning |
|---|---|---|---|
| Dữ liệu sử dụng | Toàn bộ dữ liệu có nhãn | Kết hợp dữ liệu có nhãn và chưa có nhãn | Chủ yếu dùng dữ liệu chưa gắn nhãn |
| Chi phí chuẩn bị dữ liệu | Cao | Thấp hơn đáng kể | Thấp |
| Độ chính xác | Thường rất cao nếu dữ liệu lớn | Có thể gần tương đương Supervised Learning | Thấp hơn trong nhiều tác vụ dự đoán |
| Khả năng mở rộng | Tốn nhiều công sức gắn nhãn | Dễ mở rộng với dữ liệu lớn | Rất dễ mở rộng |
| Độ phức tạp huấn luyện | Trung bình | Cao hơn do cần xử lý dữ liệu chưa nhãn | Trung bình |
| Ứng dụng phổ biến | Phân loại ảnh, dự đoán dữ liệu | AI quy mô lớn, chatbot, Computer Vision | Clustering, phân tích hành vi |
| Phụ thuộc con người | Rất cao | Trung bình | Thấp |
| Khả năng tận dụng dữ liệu internet | Hạn chế nếu thiếu nhãn | Rất tốt | Tốt |
| Nhu cầu GPU AI | Cao | Rất cao với mô hình lớn | Trung bình đến cao |
| Ví dụ thực tế | Spam email, nhận diện ảnh | Xe tự lái, AI y tế, Generative AI | Gợi ý sản phẩm, phân nhóm dữ liệu |
Ứng dụng thực tế của Semi-Supervised Learning
Semi-Supervised Learning hiện được sử dụng trong rất nhiều trong lĩnh vực công nghệ. Trong xe tự lái, hệ thống AI phải xử lý khối lượng video khổng lồ từ camera giao thông. Việc gắn nhãn thủ công cho từng khung hình gần như không khả thi, nên Semi-Supervised Learning giúp mô hình tận dụng dữ liệu chưa được phân loại để cải thiện khả năng nhận diện vật thể.
Trong AI y tế, mô hình có thể học từ hàng triệu ảnh MRI hoặc X-quang dù chỉ một phần nhỏ được bác sĩ chú thích chi tiết. Điều này giúp tăng tốc quá trình phát triển AI hỗ trợ chẩn đoán bệnh.
Trên mạng xã hội, AI moderation (giám sát các hành vi độc hại bằng AI) sử dụng Semi-Supervised Learning để phát hiện nội dung độc hại nhanh hơn trên lượng dữ liệu cực lớn. Các chatbot AI hiện đại cũng tận dụng kỹ thuật này để học từ lượng văn bản khổng lồ trên internet.
Lợi thế và điểm yếu của phương pháp Học bán giám sát
Ưu điểm của Semi-Supervised Learning
Ưu điểm lớn nhất của Semi-Supervised Learning là giảm đáng kể chi phí dữ liệu. Thay vì phải gắn nhãn toàn bộ dataset, doanh nghiệp chỉ cần xử lý một phần nhỏ dữ liệu nhưng vẫn đạt độ chính xác cao.
Ngoài ra, phương pháp này còn giúp tận dụng dữ liệu lớn hiệu quả hơn, tăng khả năng mở rộng AI và rút ngắn thời gian chuẩn bị dữ liệu. Trong nhiều trường hợp, Semi-Supervised Learning có thể đạt kết quả gần tương đương Supervised Learning dù sử dụng ít dữ liệu có nhãn hơn nhiều.
Hạn chế của Semi-Supervised Learning
Dù mạnh mẽ, Semi-Supervised Learning vẫn tồn tại nhiều thách thức. Nếu AI tạo pseudo labels sai quá nhiều, mô hình có thể học lệch và giảm độ chính xác.
Ngoài ra, dữ liệu nhiễu cũng có thể gây lỗi lớn trong quá trình training. Việc tối ưu mô hình thường khá phức tạp và vẫn cần GPU mạnh để xử lý training quy mô lớn. Đây là lý do các hệ thống AI doanh nghiệp thường sử dụng hạ tầng GPU chuyên dụng để đảm bảo quá trình huấn luyện ổn định.
Tương lai của Semi-Supervised Learning
Khi dữ liệu toàn cầu tiếp tục tăng nhanh, Semi-Supervised Learning gần như chắc chắn sẽ trở thành một phần quan trọng của AI hiện đại. Nhiều chuyên gia xem đây là hướng đi giúp AI giảm phụ thuộc vào dữ liệu gắn nhãn thủ công và tiến gần hơn đến khả năng tự học giống con người.
Trong tương lai, các mô hình AI có thể học từ khối dữ liệu khổng lồ trên internet với lượng dữ liệu gắn nhãn tối thiểu, giúp giảm mạnh chi phí phát triển AI trên toàn cầu.
>>> Xem thêm AI Data Center là gì? Tất cả những gì bạn cần biết
Tổng kết
Semi-Supervised Learning đang trở thành một trong những công nghệ quan trọng giúp AI hiện đại tận dụng dữ liệu chưa gắn nhãn để giảm chi phí training và mở rộng khả năng học trên quy mô lớn. Khi các mô hình AI ngày càng cần nhiều tài nguyên xử lý hơn, hạ tầng GPU mạnh sẽ đóng vai trò cực kỳ quan trọng để đảm bảo tốc độ training ổn định và tối ưu hiệu suất.
Dù giúp giảm nhu cầu dữ liệu gắn nhãn, Semi-Supervised Learning vẫn yêu cầu lượng tính toán rất lớn vì mô hình phải xử lý thêm khối dữ liệu chưa được phân loại.

Server GPU NVIDIA A100 tại VNSO
Nếu bạn đang tìm kiếm hạ tầng AI mạnh Machine Learning, VNSO cung cấp Cloud GPU NVIDIA A100 chỉ từ 59K/giờ cùng dịch vụ thuê Server GPU hiệu năng.
Lợi ích khi thuê Cloud GPU và Server GPU AI tại VNSO
- Cloud GPU NVIDIA A100 chỉ từ 59K/giờ.
- Triển khai nhanh, có thể sử dụng gần như ngay lập tức.
- Hạ tầng tối ưu cho PyTorch, TensorFlow và workload AI hiện đại. Kho Model AI VNSO cài sẵn.
- Dễ dàng mở rộng tài nguyên GPU theo nhu cầu thực tế.
- Hỗ trợ thuê Server GPU riêng cho doanh nghiệp.
- Băng thông tốc độ cao, phù hợp workload AI liên tục.
>>> Điền thông tin để nhận tư vấn từ các chuyên gia AI VNSO, luôn sẵn sàng giải đáp mọi thắc mắc của bạn.
Các câu hỏi thường gặp về Semi-Supervised Learning (FAQ)
Semi-Supervised Learning phù hợp với loại dữ liệu nào?
Phương pháp này đặc biệt phù hợp với dữ liệu lớn nhưng khó gắn nhãn thủ công như hình ảnh, video, văn bản, âm thanh hoặc dữ liệu cảm biến. Đây là lý do Semi-Supervised Learning được sử dụng nhiều trong AI thị giác máy tính và chatbot.
Semi-Supervised Learning có thể thay thế hoàn toàn dữ liệu có nhãn không?
Không. AI vẫn cần một phần dữ liệu có nhãn để học các đặc điểm cơ bản ban đầu. Tuy nhiên, lượng dữ liệu cần gắn nhãn có thể giảm đáng kể so với Supervised Learning truyền thống.
Vì sao doanh nghiệp AI quan tâm đến Semi-Supervised Learning?
Doanh nghiệp thường sở hữu lượng dữ liệu rất lớn nhưng thiếu nguồn lực để phân loại toàn bộ. Semi-Supervised Learning giúp tận dụng dữ liệu sẵn có hiệu quả hơn, từ đó giảm chi phí và rút ngắn thời gian phát triển AI.
Semi-Supervised Learning có dùng trong Generative AI không?
Có. Nhiều mô hình Generative AI hiện đại tận dụng các kỹ thuật Semi-Supervised Learning để học từ lượng dữ liệu internet khổng lồ mà không cần gắn nhãn toàn bộ dữ liệu đầu vào.
Semi-Supervised Learning có khó triển khai không?
Mức độ triển khai phụ thuộc vào quy mô dữ liệu và mô hình AI. Với các hệ thống lớn, doanh nghiệp thường cần GPU AI mạnh cùng hạ tầng training chuyên dụng để tối ưu hiệu suất.
Những ngành nào ứng dụng Học bán giám sát nhiều nhất?
Các lĩnh vực sử dụng nhiều nhất hiện nay gồm AI y tế, xe tự lái, fintech, chatbot, phân tích video, nhận diện hình ảnh và kiểm duyệt nội dung mạng xã hội.
Học bán giám sát có giúp giảm thời gian training không?
Trong nhiều trường hợp, có. Doanh nghiệp không cần dành quá nhiều thời gian để gắn nhãn dữ liệu thủ công trước khi huấn luyện AI, giúp đẩy nhanh quá trình phát triển mô hình.
Framework nào phổ biến cho Semi-Supervised Learning?
Nhiều mô hình hiện được phát triển trên PyTorch và TensorFlow nhờ khả năng hỗ trợ Deep Learning, distributed training và GPU acceleration hiệu quả.
Thông tin liên hệ
Để tìm hiểu thông tin về các giải pháp AI, Máy chủ, và Điện toán đám mây… Quý khách vui lòng liên hệ chúng tôi theo thông tin dưới đây:
CÔNG TY CỔ PHẦN CÔNG NGHỆ VNSO – SINCE 2015
– Website: https://vnso.vn/
– Fanpage: Facebook | LinkedIn | YouTube | TikTok
– Hotline: 0927 444 222 | Email: info@vnso.vn
– Trụ sở: Lô O số 10, Đường số 15, KDC Miếu Nổi, Phường Gia Định, TP. Hồ Chí Minh
– VPGD Đà Nẵng: 30 Nguyễn Hữu Thọ, Phường Hải Châu, Đà Nẵng
– VPGD Hà Nội: 132 Vũ Phạm Hàm, Phường Yên Hòa, Hà Nội










