
TensorFloat-32 là gì? Cách NVIDIA A100 tăng tốc AI với TF32
28/05/2026GPU AI ngày nay không còn chỉ cạnh tranh về VRAM hay số lượng lõi CUDA cores, mà còn phải có khả năng xử lý tensor operation (phép toán tensor) hiệu quả hơn. Đó cũng là lý do NVIDIA phát triển TensorFloat-32 (TF32) trên kiến trúc Ampere và triển khai mạnh nhất trên NVIDIA A100 Tensor Core GPU.
Nghe có vẻ phức tạp, bài viết này sẽ giải đáp các câu hỏi xoay quanh TF32, một định dạng thường được nhắc đến nhưng ít ai nắm rõ nó là gì.
TensorFloat-32 (TF32) là gì?
TensorFloat-32, thường được gọi là TF32, là chế độ tính toán được NVIDIA giới thiệu cùng kiến trúc Ampere vào năm 2020. Công nghệ này được thiết kế để tăng tốc các workload FP32 trong Deep Learning bằng cách đưa chúng chạy trên Tensor Cores thay vì chỉ sử dụng CUDA cores truyền thống. Theo NVIDIA Developer, TF32 được tạo ra nhằm tăng throughput cho AI training mà vẫn giữ độ ổn định gần giống FP32.
Điểm đặc biệt của TF32 nằm ở cách nó kết hợp exponent của FP32 với mantissa có độ chính xác gần FP16. Nói đơn giản hơn, TF32 cố gắng giữ phạm vi biểu diễn số rộng như FP32 nhưng giảm bớt độ chính xác trong quá trình multiply để Tensor Cores có thể xử lý nhanh hơn rất nhiều.
Nếu so sánh dễ hiểu:
FP32 có độ chính xác cao nhưng tốc độ chậm hơn. FP16 có tốc độ rất nhanh nhưng đôi khi thiếu ổn định trong các AI model lớn. TF32 nằm giữa hai định dạng này, giúp cân bằng giữa tốc độ và độ chính xác.
NVIDIA mô tả TF32 như một chế độ “giống FP32 nhưng chạy nhanh hơn nhờ Tensor Cores”. Điều quan trọng là AI developer gần như không cần rewrite toàn bộ pipeline (tái cấu trúc lại toàn bộ một chuỗi các bước xử lý tự động trong một hệ thống AI) để tận dụng công nghệ này. Vì vậy TF32 nhanh chóng trở thành một trong những tính năng nổi bật nhất của GPU A100.
>>> Xem thêm NVIDIA A100 là gì? Phân tích GPU AI tiêu chuẩn của mọi Data Center
Vì sao NVIDIA tạo ra TF32?
Trước khi Ampere xuất hiện, AI training thường gặp một giới hạn lớn. FP32 đủ ổn định cho Deep Learning nhưng tốc độ không còn theo kịp quy mô AI model ngày càng lớn. Trong khi đó, Tensor Cores trên Volta và Turing chủ yếu tối ưu cho FP16 mixed precision. Điều này khiến developer phải tuning nhiều hơn, chỉnh sửa pipeline phức tạp hơn và đôi khi gặp vấn đề numerical stability.
TF32 được NVIDIA tạo ra để giải quyết chính khoảng trống này. Thay vì yêu cầu toàn bộ workload phải chuyển sang FP16, NVIDIA cho phép input và output vẫn giữ định dạng FP32 nhưng tensor computation bên trong sẽ được tối ưu theo TF32 trên Tensor Cores.
Kết quả là AI training có thể tăng tốc đáng kể mà không cần thay đổi workflow quá nhiều. Đây là một trong những yếu tố giúp NVIDIA A100 nhanh chóng trở thành GPU AI phổ biến trong giai đoạn bùng nổ Deep Learning và AI datacenter.
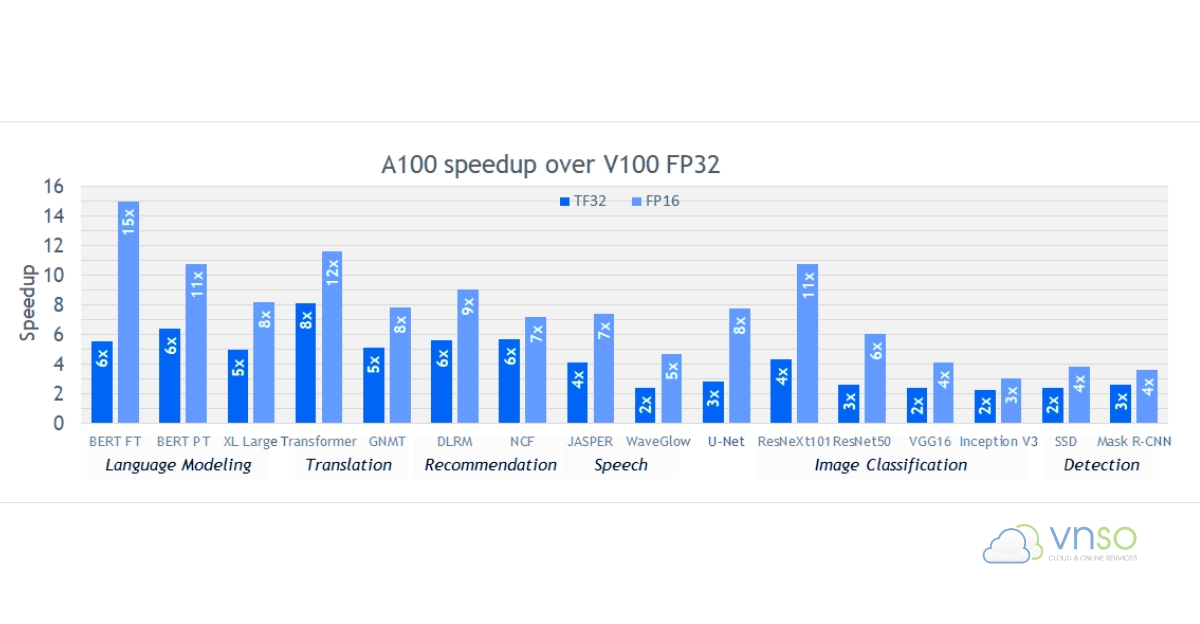
Biểu đồ thể hiện mức tăng tốc AI training của NVIDIA A100 so với V100 FP32 trên PyTorch, TensorFlow và MXNet.
NVIDIA A100 Tensor Cores hoạt động với TensorFloat-32 như thế nào?
Tensor Cores là các nhân xử lý chuyên biệt trên GPU NVIDIA dùng để tăng tốc tensor operation, đặc biệt là matrix multiplication (nhân ma trận). Đây là dạng phép toán xuất hiện liên tục trong Deep Learning và thường chiếm phần lớn khối lượng tính toán khi train AI model.
Trên kiến trúc Ampere, NVIDIA trang bị Tensor Cores thế hệ thứ ba cho A100 với hỗ trợ TF32, FP16, BF16, FP64 Tensor Core, INT8 và INT4. Theo NVIDIA, Ampere là thế hệ đầu tiên hỗ trợ TF32 trực tiếp trên Tensor Cores.
Điểm quan trọng nằm ở việc nhiều framework AI hiện đại như TensorFlow, PyTorch, cuDNN hay cuBLAS có thể tự động tận dụng TF32 mà không cần rewrite model lớn. NVIDIA cũng cho biết TF32 hiện là default precision trong cuDNN trên Ampere. Điều này đồng nghĩa rất nhiều AI workload đã tự động được tăng tốc trên A100 ngay cả khi developer không chủ động tối ưu Tensor Cores riêng.
Có thể hiểu đơn giản rằng TF32 đã biến Tensor Cores từ một tính năng chuyên biệt dành cho mixed precision trở thành nền tảng tăng tốc gần như mặc định cho Deep Learning hiện đại.
Điểm khác biệt của TF32 so với FP32, FP16 và BF16?
TF32, FP32, FP16 và BF16 là các định dạng dữ liệu dấu phẩy động (floating-point) được sử dụng trong máy tính để biểu diễn các số thực, đặc biệt quan trọng trong lĩnh vực Trí tuệ Nhân tạo (AI) và Học máy (Machine Learning)
Nhiều người thường nhầm TF32 là “FP32 mới”, nhưng thực tế không hoàn toàn như vậy. FP32 từng là tiêu chuẩn mặc định cho AI training nhờ độ chính xác và tính ổn định cao. Tuy nhiên throughput của FP32 thấp hơn rất nhiều so với Tensor Cores.
FP16 lại có tốc độ cực nhanh và tiết kiệm VRAM hơn nhưng dễ gặp vấn đề overflow hoặc underflow khi train model lớn.
BF16 được thiết kế để giữ exponent rộng giống FP32 nên ổn định hơn FP16 trong nhiều workload AI hiện đại.
Trong khi đó, TF32 được thiết kế riêng cho Tensor Cores trên Ampere nhằm tăng tốc workload FP32 mà không buộc developer phải thay đổi quá nhiều pipeline hiện có. Đây là điểm khiến TF32 khác biệt so với các định dạng precision còn lại.
Một chi tiết quan trọng là TF32 không thay thế hoàn toàn FP32. Theo nhiều kỹ sư CUDA và thảo luận kỹ thuật, TF32 chủ yếu tăng tốc tensor operation, đặc biệt là matrix multiplication. Những phép toán FP32 thông thường khác vẫn tiếp tục chạy bằng pipeline FP32 truyền thống.
Vì sao TensorFloat-32 trở thành công nghệ quan trọng trên NVIDIA A100?
Khi NVIDIA A100 Tensor Core GPU ra mắt, thay đổi lớn nhất nằm ở Tensor Cores thế hệ thứ ba và TensorFloat-32 (TF32). Đây là công nghệ giúp A100 tạo ra bước nhảy vọt lớn về hiệu năng trong cả AI, HPC (High Performance Computing) và scientific computing.
Trước Ampere, Tensor Cores chủ yếu được xem là công nghệ dành cho mixed precision training. Điều này khiến developer thường phải chuyển workload sang FP16 hoặc tối ưu pipeline khá phức tạp để tận dụng hết sức mạnh phần cứng. Với nhiều doanh nghiệp và nhóm phát triển AI lớn, đây là rào cản không nhỏ vì việc thay đổi precision có thể ảnh hưởng đến stability của model.
TF32 giúp tăng tốc AI và Deep Learning mạnh hơn nhiều thế hệ trước
Theo NVIDIA, A100 có thể mang lại hiệu năng AI training cao hơn tới 20 lần trong một số workload so với GPU Volta thế hệ trước. Mức tăng tốc này đến từ nhiều yếu tố kết hợp như Tensor Cores thế hệ thứ ba, TF32, structured sparsity acceleration và băng thông bộ nhớ cực cao của HBM2e.
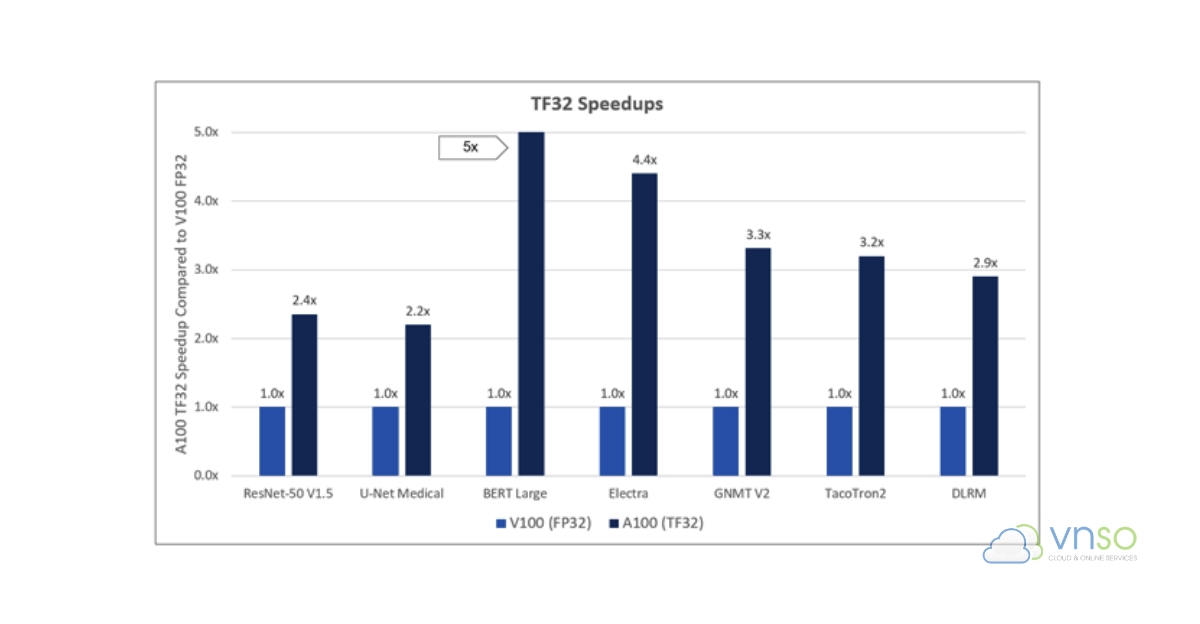
Biểu đồ cho thấy mức tăng tốc thời gian xử lý mà A100 với TF32 có thể đạt được so với V100 dùng FP32
Riêng TF32 đã giúp throughput tensor operation cao hơn rất nhiều so với FP32 truyền thống. Theo thông số chính thức, A100 PCIe đạt khoảng 156 TFLOPS TF32, trong khi A100 SXM có thể đạt khoảng 312 TFLOPS TF32 với sparsity acceleration. Trong khi đó, FP32 CUDA core truyền thống trên A100 chỉ đạt khoảng 19.5 TFLOPS.
Benchmark từ NVIDIA Developer cũng cho thấy nhiều AI model phổ biến đạt speedup rất lớn khi dùng TF32 trên A100. Một số workload như BERT training có thể nhanh hơn khoảng 5–6 lần so với FP32 trên Volta. Trung bình 23 neural network benchmark của NVIDIA đạt khoảng 2.6 lần tăng tốc với TF32.
Điều này đặc biệt quan trọng với AI datacenter vì training hiện đại thường kéo dài hàng giờ hoặc hàng ngày. Khi thời gian train giảm mạnh, doanh nghiệp cũng tiết kiệm đáng kể chi phí hạ tầng, điện năng và thời gian triển khai model.
>>> Xem thêm Top 10 Ứng dụng thực tiễn của NVIDIA Ampere A100
TensorFloat-32 mở rộng vai trò của Tensor Cores ngoài AI training
Dù TF32 nổi tiếng nhất trong Deep Learning, công nghệ này còn rất quan trọng với nhiều workload matrix-heavy ngoài AI.
Theo NVIDIA, Tensor Cores với TF32 cũng được dùng trong HPC và scientific computing để tăng tốc các phép toán ma trận lớn, iterative solver, numerical simulation và nhiều workload tính toán khoa học phức tạp.
Một số lĩnh vực hưởng lợi từ TF32 gồm:
- Mô phỏng vật lý
- Mô phỏng chất lỏng Fluid dynamics
- Mô phỏng, dự đoán thời tiết Weather simulation
- Mô hình hóa phân tử Molecular modeling
- Hệ thống gợi ý Recommendation system
- Xử lý Ngôn ngữ Tự nhiên NLP
- Computer vision (Thị giác máy tính)
- Tính toán ma trận khoa học Scientific matrix computation
TF32 giúp doanh nghiệp tận dụng GPU AI dễ dàng hơn
Một lợi ích rất lớn của TF32 là giảm đáng kể độ phức tạp khi tối ưu AI workload.
Trước đây, để tận dụng Tensor Cores hiệu quả, developer thường phải triển khai mixed precision training hoặc tối ưu precision khá sâu trong pipeline. Với TF32, nhiều framework có thể tự động tăng tốc tensor operation mà vẫn giữ workflow gần giống FP32 truyền thống.
Điều này giúp giảm thời gian tối ưu model và nguy cơ lỗi. Đồng thời, tăng khả năng tương thích với code cũ và đơn giản hóa quá trình migration sang GPU Ampere. TF32 được xem là bước chuyển lớn giúp GPU AI dễ tiếp cận hơn với doanh nghiệp và tổ chức nghiên cứu quy mô lớn.
TensorFloat-32 hiện còn quan trọng không?
Dù hiện nay H100 và Blackwell đã xuất hiện, TF32 vẫn là công nghệ rất quan trọng trong AI infrastructure. Rất nhiều datacenter vẫn sử dụng NVIDIA A100 Tensor Core GPU cho AI training và inference. TensorFlow, PyTorch cùng nhiều framework AI hiện đại vẫn tiếp tục hỗ trợ TF32. Ngoài ra, nhiều doanh nghiệp vẫn ưu tiên sự ổn định gần FP32 thay vì chuyển hoàn toàn sang các định dạng có độ chính xác (precision) thấp hơn.
TF32 cũng giúp chuyển sang sử dụng Tensor Cores đơn giản hơn rất nhiều, đặc biệt với các dự án AI lớn đã xây dựng trên FP32 trong nhiều năm.
Kết luận
TensorFloat-32 (TF32) là một trong những công nghệ quan trọng nhất giúp NVIDIA A100 trở thành GPU AI nổi bật của thời kỳ Deep Learning hiện đại. Thay vì buộc developer phải chuyển hoàn toàn sang FP16 mixed precision, TF32 cho phép workload FP32 tận dụng Tensor Cores gần như tự động.
Nhờ đó, NVIDIA A100 có thể tăng tốc AI training mạnh hơn nhiều thế hệ trước mà vẫn giữ compatibility cao với hệ sinh thái Deep Learning hiện có. Đây cũng là lý do TF32 thường được xem là bước chuyển giúp Tensor Cores từ một tính năng chuyên biệt trở thành nền tảng tăng tốc mặc định cho AI training hiện đại.
Bạn có thể triển khai AI, train model hoặc inference với NVIDIA A100 Cloud GPU VNSO chỉ từ 59.000 VNĐ/giờ.
Khởi tạo nhanh trong 5 phút, hỗ trợ sẵn CUDA, PyTorch, TensorFlow và kho model AI cài sẵn như Llama hay Stable Diffusion. Hạ tầng GPU đặt tại Việt Nam giúp giảm độ trễ, đi kèm uptime 99.9%, hỗ trợ kỹ thuật 24/7 và tính năng độc quyền cho phép dừng máy tới 72 giờ mà không mất dữ liệu hay tốn thêm chi phí lưu trạng thái môi trường AI.
>>> Điền thông tin để nhận tư vấn từ các chuyên gia AI VNSO, giải đáp mọi thắc mắc của bạn.
Các câu hỏi thường gặp về TensorFloat-32 (FAQ)
TensorFloat-32 có phải là định dạng thay thế hoàn toàn FP32 không?
Không. TF32 không được thiết kế để thay thế hoàn toàn FP32. NVIDIA tạo TF32 chủ yếu để tăng tốc tensor operation trên Tensor Cores, đặc biệt là matrix multiplication trong AI và HPC. Nhiều phép toán FP32 thông thường khác vẫn tiếp tục chạy bằng pipeline FP32 truyền thống.
TF32 có làm giảm độ chính xác của AI model không?
Có, nhưng mức giảm thường khá nhỏ trong nhiều workload Deep Learning hiện đại. TF32 sử dụng mantissa gần với FP16 để tăng tốc Tensor Cores nên độ chính xác thấp hơn FP32 thuần túy. Tuy nhiên NVIDIA cho biết phần lớn AI model phổ biến vẫn giữ độ hội tụ và accuracy gần giống FP32 trong quá trình training.
TF32 có phải mixed precision không?
Không hoàn toàn. TF32 khác với mixed precision training truyền thống dùng FP16 hoặc BF16. Với TF32, input và output vẫn dùng FP32, trong khi Tensor Cores tối ưu phần tensor computation bên trong để tăng throughput.
GPU nào hỗ trợ TensorFloat-32?
TF32 được NVIDIA giới thiệu cùng kiến trúc Ampere. Các GPU hỗ trợ TF32 gồm:
- NVIDIA A100
- A30
- A40
- RTX A6000
- GeForce RTX 30 series
- Và nhiều GPU datacenter và workstation dùng kiến trúc Ampere trở lên
TensorFloat-32 có hoạt động trên GPU Volta hoặc Turing không?
Không. TF32 được hỗ trợ từ Tensor Cores thế hệ thứ ba trên Ampere. Các GPU Volta hoặc Turing không hỗ trợ TF32 native hardware như A100.
TF32 có giúp inference nhanh hơn không?
Có. Ngoài AI training, TF32 cũng có thể tăng tốc inference trong một số workload sử dụng TensorRT, cuDNN hoặc matrix-heavy operation. Tuy nhiên nhiều hệ thống inference hiện đại vẫn ưu tiên FP16 hoặc INT8 để đạt throughput cao hơn.
TF32 có tiết kiệm VRAM như FP16 không?
Không nhiều. Vì workflow TF32 vẫn giữ input và output theo chuẩn FP32 nên mức tiết kiệm bộ nhớ không lớn như FP16 hoặc BF16. Điểm mạnh chính của TF32 là tăng tốc tensor operation mà vẫn giữ compatibility gần FP32.
Vì sao NVIDIA không dùng FP16 hoàn toàn thay cho TF32?
FP16 rất nhanh nhưng không phải workload nào cũng ổn định khi dùng precision thấp hơn. Một số AI model lớn hoặc scientific workload có thể gặp overflow, underflow hoặc mất stability. TF32 được tạo ra để cân bằng giữa hiệu năng và độ ổn định mà không yêu cầu developer tối ưu mixed precision quá sâu.
TensorFloat-32 có phù hợp với scientific computing không?
Có. NVIDIA cho biết TF32 còn được dùng trong HPC và scientific computing để tăng tốc các workload phụ thuộc mạnh vào matrix multiplication và tensor operation. Một số ứng dụng phổ biến gồm mô phỏng vật lý, fluid dynamics, molecular modeling và numerical simulation.
TensorFloat-32 có còn quan trọng khi H100 và Blackwell xuất hiện?
Có. Dù các GPU mới hiện nay đã hỗ trợ nhiều định dạng mạnh hơn như FP8, TF32 vẫn rất quan trọng vì NVIDIA A100 vẫn được triển khai rộng trong AI datacenter và cloud GPU infrastructure trên toàn cầu.
TF32 có tự động bật trên PyTorch và TensorFlow không?
Trong nhiều trường hợp là có. Các framework như PyTorch, TensorFlow, cuDNN và cuBLAS hiện đều hỗ trợ TF32 trên Ampere. Một số framework sẽ tự động kích hoạt TF32 Tensor Cores mặc định để tăng tốc workload AI.
TensorFloat-32 có phải chỉ dành cho AI không?
Không. Dù nổi tiếng nhất trong Deep Learning, TF32 còn được dùng trong HPC, scientific computing và nhiều workload matrix-heavy khác. Bất kỳ ứng dụng nào phụ thuộc mạnh vào matrix multiplication đều có thể hưởng lợi từ Tensor Cores và TF32.
Thông tin liên hệ
Để tìm hiểu thông tin về các giải pháp AI, Máy chủ, và Điện toán đám mây… Quý khách vui lòng liên hệ chúng tôi theo thông tin dưới đây:
CÔNG TY CỔ PHẦN CÔNG NGHỆ VNSO – SINCE 2015
– Website: https://vnso.vn/
– Fanpage: Facebook | LinkedIn | YouTube | TikTok
– Hotline: 0927 444 222 | Email: info@vnso.vn
– Trụ sở: Lô O số 10, Đường số 15, KDC Miếu Nổi, Phường Gia Định, TP. Hồ Chí Minh
– VPGD Đà Nẵng: 30 Nguyễn Hữu Thọ, Phường Hải Châu, Đà Nẵng
– VPGD Hà Nội: 132 Vũ Phạm Hàm, Phường Yên Hòa, Hà Nội










