Một GPU như NVIDIA A100 có giá hàng chục nghìn USD, chưa tính chi phí vận hành, khiến nhiều doanh nghiệp khó tiếp cận. Thay vì đầu tư lớn ngay từ đầu, bạn có thể thuê NVIDIA A100 Cloud GPU VNSO theo giờ với chi phí chỉ từ 29.000 VNĐ/giờ (Cập nhật vào tháng 6, năm 2026), sẵn sàng sử dụng trong 5 phút.
Bài viết dưới đây sẽ giúp bạn hiểu rõ Card NVIDIA A100 là gì, vì sao nó được sử dụng rộng rãi trong các hạ tầng AI, Datacenter tại Việt Nam và cách tận dụng tối đa Cloud GPU A100 để có hiệu suất cao và vừa tiết kiệm chi phí!
>>> Bạn đang cần thuê Cloud GPU NVIDIA A100 giá tốt? Hãy để lại thông tin để VNSO liên hệ hỗ trợ tư vấn, báo giá!

Triển khai, thuê Cloud GPU và Server GPU hiệu quả cùng VNSO
Table of Content (Mục lục)
- NVIDIA A100 là gì? Cloud GPU là gì? Điểm khác biệt
- Thông số kỹ thuật NVIDIA A100 40GB vs 80GB
- Bảng giá Cloud GPU VNSO (2026)
- Hiệu năng & điểm mạnh của NVIDIA A100
- Use case & case study thực tế
- Ứng dụng của NVIDIA A100
- So sánh Cloud GPU vs. Server GPU, Khi nào nên thuê A100 Cloud GPU?
- Điểm mạnh Cloud GPU VNSO
- Câu hỏi thường gặp (FAQ)
- Call to Action / Liên hệ
GPU NVIDIA A100 là gì?
NVIDIA A100 là GPU datacenter được thiết kế cho các tác vụ tính toán nặng như AI, machine learning và xử lý dữ liệu lớn. Khác với GPU thông thường dùng cho đồ họa hoặc gaming, A100 tập trung vào khả năng xử lý song song, ưu tiên hiệu năng tính toán, độ ổn định khi chạy liên tục 24/7 và khả năng mở rộng trong hệ thống nhiều GPU.
CPU xử lý từng tác vụ theo thứ tự, GPU NVIDIA A100 có thể xử lý nhiều tác vụ cùng lúc, từ đó rút ngắn đáng kể thời gian tính toán. Nhờ đặc điểm này, A100 hiện được sử dụng rộng rãi trong các hệ thống AI như chatbot, nhận diện hình ảnh và phân tích dữ liệu.
Thuê NVIDIA A100 là hình thức sử dụng GPU datacenter NVIDIA A100 thông qua cloud thay vì phải mua và lắp đặt phần cứng. Bạn có thể truy cập GPU từ xa, sử dụng theo giờ/ngày và trả phí theo mức dùng thực tế. Mô hình này giúp triển khai AI, machine learning nhanh chóng, không cần đầu tư ban đầu và dễ dàng mở rộng khi nhu cầu tăng.
Điểm khác biệt của Cloud GPU
Cloud GPU là mô hình cung cấp GPU qua internet dưới dạng dịch vụ. Thay vì mua và lắp đặt phần cứng, người dùng có thể thuê GPU AI trong datacenter, truy cập từ xa và trả phí theo thời gian sử dụng. Cách tiếp cận này giúp triển khai nhanh chóng và hiệu quả.
Vì vậy, Cloud GPU là cách tiếp cận hạ tầng AI hiện đại, nơi hiệu năng cao được cung cấp theo nhu cầu, sẵn sàng sử dụng ngay khi cần.
Thông số kỹ thuật, cấu hình của NVIDIA A100 PCIe Tensor Core GPU 40GB và 80GB
Từ thông số gốc của NVIDIA A100, có thể thấy bản 40GB và 80GB sử dụng cùng một GPU GA100 nên hiệu năng tính toán gần như tương đương, bao gồm số CUDA cores, Tensor cores và TFLOPS.
Khác biệt chủ yếu nằm ở dung lượng VRAM và băng thông bộ nhớ, trong đó bản 80GB cho phép xử lý mô hình AI lớn hơn, batch size cao hơn và giảm giới hạn bộ nhớ khi chạy LLM hoặc workload nặng. Vì vậy, lựa chọn giữa hai phiên bản phụ thuộc vào nhu cầu dữ liệu và độ lớn mô hình cần.
| Hạng mục |
NVIDIA A100 40GB |
NVIDIA A100 80GB |
| Kiến trúc |
Ampere (GA100) |
Ampere (GA100) |
| Tiến trình |
7nm (TSMC) |
7nm (TSMC) |
| Số transistor |
~54 tỷ |
~54 tỷ |
| CUDA Cores |
6,912 |
6,912 |
| Tensor Cores |
432 (Gen 3) |
432 (Gen 3) |
| VRAM |
40GB HBM2 |
80GB HBM2e |
| Băng thông bộ nhớ |
~1,555 GB/s |
~1,935–2,039 GB/s |
| FP32 |
~19.5 TFLOPS |
~19.5 TFLOPS |
| FP64 |
~9.7 TFLOPS |
~9.7 TFLOPS |
| Tensor (TF32) |
~156 TFLOPS |
~156–312 TFLOPS |
| Tensor (FP16/BF16) |
~312 TFLOPS |
~312–624 TFLOPS |
| INT8 |
~624 TOPS |
~624–1248 TOPS |
| L2 Cache |
~40 MB |
~40 MB |
| NVLink |
600 GB/s |
600 GB/s |
| PCIe |
Gen4 |
Gen4 |
| MIG (Multi-Instance GPU) |
Tối đa 7 instance (5GB/instance) |
Tối đa 7 instance (10GB/instance) |
| TDP |
~250W (PCIe) / 400W (SXM) |
~300W (PCIe) / 400W (SXM) |
Bảng giá và cấu hình dịch vụ thuê NVIDIA A100 Cloud GPU VNSO (2026)
A100 40GB tối ưu chi phí với mức thuê GPU theo giờ chỉ 29.000 VNĐ đủ cho đa số workload AI phổ biến, còn A100 80GB có giá cao nhưng gấp đôi VRAM và tài nguyên, phù hợp model lớn và production. Nếu không bị giới hạn VRAM thì 40GB là lựa chọn hiệu quả, còn nếu làm LLM hoặc dataset lớn thì 80GB đáng tiền hơn.
| Thành phần |
A100 40GB |
A100 80GB |
| GPU |
1x NVIDIA A100 |
1x NVIDIA A100 |
| VRAM |
40 GB |
80 GB |
| RAM hệ thống |
48 GB |
96 GB |
| CPU |
16 vCPU (16 cores) |
32 vCPU (32 cores) |
| Storage |
1 TB NVMe |
2 TB NVMe |
| Giá theo giờ |
29.000 ₫ |
49.000 ₫ |
| Giá theo ngày |
Contact |
Contact |
| Giá theo tuần |
Contact |
Contact |
| Giá theo tháng |
Contact |
Contact |
>>> Xem thêm Thuê Server GPU NVIDIA A100 PCIe 40GB cho AI, Deep Learning, Inference và Training

Server AI sử dụng GPU NVIDIA A100 trong tủ Rack
Hiệu năng AI mạnh mẽ đã được kiểm chứng qua nhiều năm của NVIDIA A100
Điểm mạnh cốt lõi của A100 là sự kết hợp giữa hiệu suất tính toán mạnh (compute), băng thông cực cao, khả năng mở rộng (scale) và tối ưu tài nguyên. Đây là lý do A100 được nhiều doanh nghiệp đánh giá nhanh hơn và hiệu quả hơn trong vận hành AI thực tế, đặc biệt ở quy mô production doanh nghiệp.
Kiến trúc Ampere
A100 sử dụng kiến trúc Ampere giúp nâng cấp hiệu năng và là bước chuyển sang kiến trúc “đa mục tiêu” đầu tiên. Điểm then chốt nằm ở Tensor Core thế hệ 3 với TF32 giúp tăng tốc AI mà không cần đổi code, cùng khả năng xử lý nhiều định dạng tính toán linh hoạt. Kết luận ngắn: Ampere biến GPU từ công cụ chuyên biệt thành hạ tầng tính toán tổng quát, giúp A100 vừa mạnh, vừa dễ triển khai trong thực tế.
Structured sparsity (độ thưa có cấu trúc) trong kiến trúc Ampere là kỹ thuật tối ưu, tăng tốc AI trong đó các trọng số của mô hình được loại bỏ theo một pattern cố định (có quy luật), thay vì xóa ngẫu nhiên.
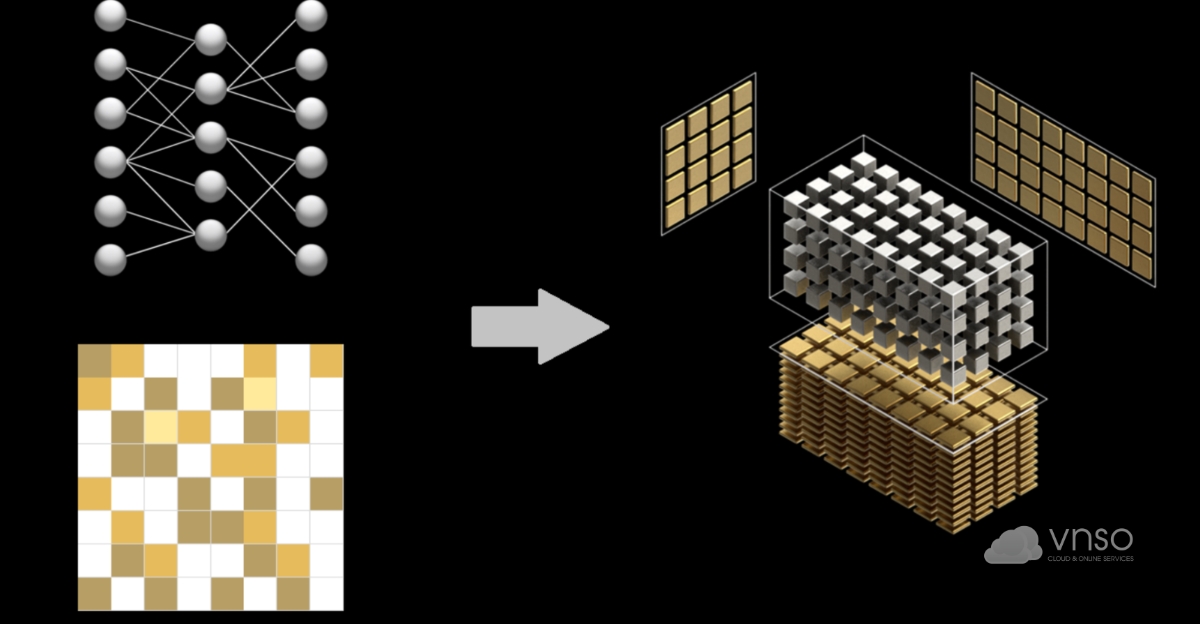
Ảnh minh họa Structured Sparsity trong kiến trúc Ampere
Hiệu năng AI vượt trội, tăng tốc thực tế chứ không chỉ lý thuyết
NVIDIA A100 mang lại bước nhảy hiệu năng rất lớn so với thế hệ trước, với mức tăng lên tới 20 lần trong một số workload AI. Trong thực tế, các mô hình NLP như BERT có thể đạt tốc độ inference, Deep Learning nhanh, giúp giảm mạnh chi phí vận hành AI production.
Training nhanh hơn, scale tới hàng nghìn GPU
A100 được thiết kế cho scale lớn, có thể kết hợp với NVLink/NVSwitch để chạy cluster hàng nghìn GPU. NVIDIA ghi nhận một bài toán BERT có thể được giải trong dưới 1 phút với 2.048 GPU A100, cho thấy khả năng mở rộng gần như tuyến tính.

Bảng so sánh tốc độ Inference Training của NVIDIA A100 so với Model cũ V100
Bộ nhớ và băng thông, lợi thế quyết định trong AI hiện đại
Phiên bản 80GB đạt băng thông hơn 2 TB/s, thuộc nhóm cao nhất trên thị trường GPU datacenter . Điều này cực kỳ quan trọng vì phần lớn workload AI (đặc biệt LLM) bị giới hạn bởi memory bandwidth hơn là compute, giúp A100 duy trì hiệu suất ổn định khi xử lý dataset và model lớn.
Chia nhỏ GPU sử dụng độc lập với công nghệ MIG (Multi-Instance)
Công nghệ Multi-Instance GPU cho phép chia một A100 thành tối đa 7 instance độc lập, giúp tăng hiệu suất sử dụng tài nguyên và đạt tới 7 lần throughput inference trong một số trường hợp. Đây là yếu tố then chốt trong môi trường thuê NVIDIA A100 cloud và nhiều user sử dụng (multi-tenant).
Điện toán hiệu năng cao (High-Performance Computing – HPC) & Phân tích dữ liệu (Data Analytics)
Ngoài AI, A100 còn tăng tốc mạnh các bài toán khoa học và dữ liệu. NVIDIA cho biết có thể giảm mô phỏng dữ liệu (simulation) từ 10 giờ xuống còn dưới 4 giờ, đồng thời đạt tới 11 lần hiệu năng cao hơn trong một số tác vụ HPC. Trong data analytics, bản 80GB cũng cho kết quả nhanh gấp 2 lần so với bản 40GB trên benchmark lớn.

Hiệu năng AI Inference nhanh gấp 249x lần CPU
Ứng dụng thực tế của NVIDIA A100 (Use case & case study)
A100 không bị giới hạn ở một lĩnh vực cụ thể. Nó xuất hiện xuyên suốt toàn bộ quy trình pipeline AI: từ training LLM, generative AI, inference production đến HPC và data analytics. Điểm chung là tất cả đều yêu cầu compute lớn, khả năng mở rộng cao và độ ổn định dài hạn.
Dưới đây là tổng hợp các ứng dụng phổ biến của NVIDIA A100 và các nghiên cứu thực tế:
- Training mô hình AI (LLM, NLP, Computer Vision)
- Fine-tuning và tối ưu model AI
- Inference production (chatbot, AI API, recommendation system)
- Generative AI (text-to-image, text-to-video, diffusion models)
- Xử lý dữ liệu lớn (big data, GPU-accelerated analytics)
- HPC (mô phỏng thời tiết, khoa học, tài chính)
- Xử lý video và streaming AI (AI video analytics)
- Rendering 3D, VFX, game engine
- Speech AI (nhận diện giọng nói, tổng hợp giọng nói)
- Autonomous systems (xe tự hành, robotics AI)
>>> Xem thêm Top 10 nhà cung cấp dịch vụ thuê Cloud GPU cho AI năm 2026

Mô hình ngôn ngữ Llama nổi tiếng
Meta (LLaMA) Training LLM quy mô lớn
Một trong những case study tiêu biểu nhất là Meta khi huấn luyện các mô hình LLaMA. Họ đã sử dụng tới 16.000 GPU A100 để training, với tổng thời gian khoảng 3,3 triệu GPU-hours cho phiên bản LLaMA 2.
Khối lượng tính toán này cho thấy A100 không chỉ dùng cho thử nghiệm mà là nền tảng thực tế để xây dựng các mô hình AI cấp độ toàn cầu.
Generative AI và Stability AI (Stable Diffusion)
Stability AI đã sử dụng 256 GPU A100 trong khoảng 200.000 giờ compute để train Stable Diffusion V2. A100 giúp huấn luyện mô hình tạo ảnh từ văn bản ở quy mô lớn, mở ra làn sóng GenAI phổ biến hiện nay.
Inference LLM tốc độ cao – Perplexity AI
Trong triển khai thực tế, Perplexity AI sử dụng A100 để phục vụ inference LLM với độ trễ thấp. Kết quả đạt được là giảm latency đáng kể và tối ưu chi phí vận hành, giúp xử lý lượng truy vấn lớn ổn định.

NVIDIA A100 trong AI doanh nghiệp của FPT Smart Cloud (Việt Nam)
Tại Việt Nam, FPT Smart Cloud ứng dụng GPU NVIDIA (bao gồm A100) để tăng tốc AI. Hệ thống của họ đạt: giảm 3 lần thời gian xử lý dữ liệu và tăng tốc speech synthesis lên 4 lần. Đây là minh chứng rõ ràng cho việc A100 được ứng dụng trực tiếp trong sản phẩm AI thương mại.
HPC & khoa học – Shell (dầu khí)
Trong lĩnh vực năng lượng, Shell sử dụng A100 để xử lý dữ liệu địa chấn và mô phỏng reservoir. Kết quả là tăng tốc phân tích dữ liệu lớn và rút ngắn thời gian tính toán từ tuần xuống còn ngày. A100 ở đây đóng vai trò GPU HPC, không chỉ AI.
MLPerf Benchmark tiêu chuẩn ngành
Trong benchmark MLPerf (tiêu chuẩn ngành AI), hệ sinh thái NVIDIA chiếm tới 90% số liệu công bố, và A100 là GPU duy nhất chạy đầy đủ tất cả các bài test từ NLP, CV đến recommendation.
A100 không chỉ là GPU mạnh trên lý thuyết mà đã được chứng minh trong các hệ thống thực tế quy mô lớn, từ Meta, Stability AI đến doanh nghiệp tại Việt Nam. Đây là lý do nó vẫn được xem là “tiêu chuẩn triển khai AI production” cho đến hiện tại.
>>> Xem thêm Top 10 thương hiệu máy chủ AI tốt nhất thế giới 2026
Thuê NVIDIA A100 Cloud GPU vs. Server GPU: nên chọn mô hình nào?
Cloud GPU là GPU thuê theo nhu cầu, triển khai nhanh và không cần đầu tư ban đầu; Server GPU là máy chủ vật lý riêng, cho hiệu năng ổn định và toàn quyền kiểm soát. Sử dụng đám mây phù hợp workload linh hoạt, còn máy chủ GPU phù hợp khi chạy liên tục 24/7.
Bảng so sánh nhanh giữa thuê NVIDIA A100 Cloud GPU và Server GPU
Cloud GPU để bắt đầu nhanh và scale linh hoạt còn Server GPU phù hợp khi workload ổn định, chạy lâu dài. Hybrid sử dụng cả 2 cũng là hướng phổ biến của các doanh nghiệp ngày nay.
| Tiêu chí |
Cloud GPU |
Server GPU |
| Chi phí đầu |
Thấp |
Cao |
| Chi phí dài hạn |
Cao nếu dùng nhiều |
Tối ưu hơn |
| Triển khai |
Vài phút |
Vài ngày–tuần |
| Scale |
Rất linh hoạt |
Hạn chế |
| Hiệu năng |
Có thể shared |
Ổn định, dedicated |
| Vận hành |
Không cần |
Tự quản lý |
>>> Xem thêm Thuê Server GPU – AI, Cloud GPU uy tín, giá tốt
Có nên thuê NVIDIA A100 Cloud GPU?
Bạn nên thuê A100 Cloud GPU khi cần xử lý AI/ML nặng nếu không muốn triển khai hạ tầng phức tạp. Mô hình này phù hợp khi training theo đợt, chạy inference có traffic biến động hoặc cần test và scale nhanh trong vài phút. Với các workload không liên tục, thuê GPU giá rẻ giúp tránh lãng phí tài nguyên và tối ưu chi phí thực tế.
Thay vì mua, thuê A100 giúp loại bỏ chi phí đầu tư ban đầu và rủi ro phần cứng lỗi thời, đồng thời cho phép tiếp cận GPU mới ngay khi cần. Mô hình trả theo sử dụng giúp linh hoạt thay đổi cấu hình, mở rộng hoặc dừng bất cứ lúc nào, phù hợp với tốc độ thay đổi nhanh của hệ thống AI hiện nay.

8x NVIDIA A100 Tensor Core 80GB GPU tại VNSO
Triển khai ngay, thuê NVIDIA A100 Cloud GPU đơn giản trong 5 phút
Dịch vụ thuê NVIDIA A100 Cloud GPU VNSO tại Việt Nam được xây dựng theo hướng “AI-ready”, nghĩa là không chỉ cung cấp GPU mà là một hạ tầng sẵn sàng triển khai thực tế. Hệ thống sử dụng GPU datacenter như NVIDIA A100 giúp đảm bảo hiệu năng cho cả training và inference production. Với thời gian khởi tạo chỉ trong khoảng 1 phút, người dùng có thể bắt đầu ngay mà không cần setup phức tạp.
VNSO cam kết uptime 99.9%, đi kèm đội ngũ kỹ thuật hỗ trợ 24/7, phù hợp cho cả cá nhân, startup đến doanh nghiệp triển khai AI. Hạ tầng đặt tại Việt Nam giúp giảm độ trễ, tối ưu khi triển khai production trong nước.
Về mặt chi phí, mô hình thuê theo giờ giúp tối ưu ngân sách, đặc biệt với các workload không liên tục. Người dùng có thể scale từ 1 GPU lên nhiều GPU nhanh chóng.
Bên cạnh đó, hệ thống được thiết kế với các tiêu chuẩn bảo mật cao, đảm bảo dữ liệu được cô lập và an toàn trong quá trình xử lý. Hiện tại, VNSO đã được tin dùng bởi hơn 1.000 khách hàng, bao gồm developer, nhà nghiên cứu và doanh nghiệp AI.
Kho Model AI sẵn có giúp rút ngắn thời gian triển khai
Dịch vụ thuê Cloud GPU VNSO cung cấp kho model AI cài sẵn (preloaded) như LLaMA, Mistral, Stable Diffusion…, giúp bạn không cần tải lại các model hàng chục, trăm GB, tránh giới hạn băng thông và rút ngắn thời gian chuẩn bị từ 1 ngày xuống chỉ trong 5 phút.
Kết hợp môi trường đã tối ưu (CUDA, PyTorch…), bạn có thể triển khai, fine-tune hoặc chạy inference gần như ngay lập tức. Ngoài ra, VNSO có hướng dẫn sử dụng cho từng Model sau khi đăng ký.
>>> Xem chi tiết tại: Kho Model AI VNSO

Hướng dẫn thuê NVIDIA A100 Cloud GPU VNSO (siêu nhanh)
Toàn bộ quy trình từ đăng ký đến sử dụng thuê Cloud GPU giá rẻ chỉ mất từ 1-5 phút, không cần cài đặt phức tạp. Bắt đầu chỉ trong vài phút với các bước cơ bản:
- Đăng ký tài khoản: tạo nhanh bằng Email hoặc Google
- Cập nhật thông tin: hoàn thiện hồ sơ (xuất hóa đơn nếu cần)
- Nạp tiền: qua MoMo / VNPAY
- Chọn gói GPU theo nhu cầu sau đó nhấn Thuê ngay
- Kết nối sử dụng: SSH vào máy, môi trường AI, Model AI đã cài sẵn.
- Theo dõi & tính phí: trả theo thời gian sử dụng thực tế
- Kết thúc phiên: dừng khi xong để tiết kiệm chi phí. Chỉ tại VNSO: Bạn có thể dừng máy đến 72 giờ mà không tốn phí, không mất dữ liệu!
>>> Xem chi tiết tại: Hướng dẫn sử dụng Cloud GPU VNSO từ A-Z
Để lại thông tin để đội ngũ VNSO tư vấn miễn phí toàn bộ quá trình triển khai AI cho riêng bạn
Giải đáp các thắc mắc và các câu hỏi thường gặp về dịch vụ thuê Cloud GPU (FAQ)
Mất bao lâu có thể sử dụng GPU sau khi đăng ký?
Chỉ mất vài phút để khởi tạo và kết nối, không cần setup phức tạp
Tính phí như thế nào?
Tính theo giờ/ngày/tháng, trả theo mức sử dụng thực tế, không cần cam kết dài hạn
Có cần cài đặt môi trường AI không?
Không, hệ thống đã cài sẵn CUDA, PyTorch, TensorFlow… sẵn sàng sử dụng
Cloud GPU có phải GPU thật không?
Có, bạn đang sử dụng GPU vật lý trong datacenter, không phải giả lập
Khi nào nên dùng A100 thay vì GPU khác?
Khi train model lớn, LLM, hoặc workload yêu cầu VRAM cao (40GB–80GB)
Thuê cloud có rẻ hơn mua GPU không?
Rẻ hơn nếu dùng không liên tục; chỉ nên mua khi chạy gần như 24/7 lâu dài
Dữ liệu có an toàn không?
Mỗi phiên sử dụng được cách ly, nhưng nên backup vì dữ liệu có thể bị xóa khi kết thúc phiên
Thông tin liên hệ
Để tìm hiểu thông tin về các giải pháp Máy chủ GPU, Cloud GPU, Hosting Linux & Windows, Máy chủ ảo Cloud VPS, Máy chủ vật lý, Colocation, Hệ thống lưu trữ, Cloud Server, Cloud Camera AI, Cloud Storage, Private Cloud, Enterprise Cloud, CDN, Anti-DDoS Website & Game… Quý khách vui lòng liên hệ chúng tôi theo thông tin dưới đây:
CÔNG TY CỔ PHẦN CÔNG NGHỆ VNSO – SINCE 2015
– Website: https://vnso.vn/
– Fanpage: Facebook | LinkedIn | YouTube | TikTok
– Hotline: 0927 444 222 | Email: info@vnso.vn
– Trụ sở: Lô O số 10, Đường số 15, KDC Miếu Nổi, Phường Gia Định, TP. Hồ Chí Minh
– VPGD Đà Nẵng: 30 Nguyễn Hữu Thọ, Phường Hải Châu, Đà Nẵng
– VPGD Hà Nội: 132 Vũ Phạm Hàm, Phường Yên Hòa, Hà Nội
Post Views: 1,081












