
Unsupervised Learning là gì? Cách AI tự học phân tích dữ liệu
28/05/2026AI hiện nay có thể nhận diện khách hàng tiềm năng, phân tích hành vi người dùng, gợi ý video trên YouTube hay phát hiện giao dịch bất thường dù không có con người “chỉ đáp án” cho từng dữ liệu. Đằng sau khả năng đó là unsupervised learning (học không giám sát), một trong những nền tảng quan trọng nhất của machine learning (máy học) hiện đại.
Khác với supervised learning, phương pháp này cho phép AI tự tìm pattern, cấu trúc và mối liên hệ ẩn trong dữ liệu mà không cần dữ liệu gắn nhãn sẵn. Đây cũng là lý do unsupervised learning ngày càng quan trọng trong AI, big data và phân tích hành vi khách hàng quy mô lớn.
Vậy unsupervised learning hoạt động như thế nào, được ứng dụng ra sao và vì sao các hệ thống AI hiện đại cần hạ tầng GPU mạnh để xử lý loại mô hình này?
Unsupervised Learning là gì?
Unsupervised Learning, hay học không giám sát, là phương pháp machine learning trong đó AI được huấn luyện bằng dữ liệu chưa gắn nhãn (unlabeled data). Thay vì học từ “đáp án có sẵn”, mô hình sẽ tự tìm ra quy luật, cấu trúc hoặc mối liên hệ giữa các dữ liệu tương đồng. Theo IBM, đây là một trong ba nhánh chính của machine learning bên cạnh supervised learning và reinforcement learning.
Trong thực tế, unsupervised learning xuất hiện ở rất nhiều hệ thống AI hiện đại. Ví dụ, AI có thể tự phân nhóm khách hàng có hành vi mua sắm giống nhau, phát hiện giao dịch ngân hàng bất thường, gợi ý nội dung trên Netflix hoặc phân tích dữ liệu cảm biến IoT để tìm lỗi hệ thống.
>>> Xem thêm Machine Learning là gì? Hướng dẫn triển khai máy học

Dữ liệu không gắn nhãn quan trọng đến mức nào?
Phần lớn dữ liệu trên internet hiện nay đều là dữ liệu không gắn nhãn. Theo nghiên cứu của Seagate, Tổng lượng dữ liệu toàn cầu dự kiến đạt khoảng 175 zettabyte (175 tỷ Gigabyte) vào năm 2025, trong đó phần lớn là dữ liệu phi cấu trúc như video, hình ảnh, âm thanh và log hệ thống.
Việc gắn nhãn dữ liệu cho AI trên thực tế rất tốn thời gian và chi phí. Nhiều dataset có quy mô quá lớn để con người xử lý thủ công, trong khi dữ liệu toàn cầu vẫn tiếp tục tăng nhanh mỗi ngày. Đây là lý do unsupervised learning trở thành một trong những hướng nghiên cứu quan trọng nhất của AI hiện đại.
Unsupervised Learning hoạt động như thế nào?
Quá trình hoạt động của unsupervised learning thường bắt đầu bằng việc AI nhận vào một lượng lớn dữ liệu chưa phân loại. Dữ liệu này có thể là hành vi mua hàng, traffic website, hình ảnh, video, log hệ thống hoặc dữ liệu cảm biến từ các thiết bị IoT.
Sau khi tiếp nhận dữ liệu, mô hình bắt đầu phân tích để tìm điểm giống nhau, xu hướng, cấu trúc ẩn và các mối liên hệ giữa dữ liệu. Ví dụ, AI có thể nhận ra rằng nhóm khách hàng thường mua laptop gaming cũng có xu hướng mua thêm chuột gaming và tai nghe.
Tiếp theo, hệ thống sẽ tự chia dữ liệu thành các nhóm có đặc điểm tương đồng. Chẳng hạn, AI có thể phân loại khách hàng thành nhóm ưu tiên giá rẻ, nhóm chi tiêu cao hoặc nhóm thường mua hàng theo khuyến mãi.
Trong suốt quá trình training, mô hình liên tục điều chỉnh để giảm khoảng cách giữa dữ liệu trong cùng nhóm và tăng sự khác biệt giữa các nhóm khác nhau. Kết quả cuối cùng là AI có thể phát hiện những pattern mà con người khó nhận thấy bằng mắt thường.
>>> Góc công nghệ mới nhất: NVIDIA Vera Rubin là gì? Tất cả những gì bạn cần biết
Các loại Unsupervised Learning phổ biến
Clustering
Clustering là kỹ thuật phổ biến nhất trong unsupervised learning, dùng để phân nhóm dữ liệu dựa trên đặc điểm tương đồng. Công nghệ này thường được ứng dụng trong phân tích khách hàng, recommendation system, phân loại hành vi người dùng và nghiên cứu thị trường.
Một số thuật toán clustering nổi tiếng hiện nay gồm K-Means, Hierarchical Clustering và DBSCAN. Theo Statista, thị trường customer analytics toàn cầu dự kiến vượt 44 tỷ USD vào năm 2027, trong đó AI clustering đóng vai trò rất lớn trong phân tích hành vi người dùng.
Dimensionality Reduction
Dữ liệu AI hiện đại thường có số chiều cực lớn, đặc biệt trong computer vision, NLP hay genomics. Dimensionality reduction giúp giảm số lượng biến nhưng vẫn giữ lại phần lớn thông tin quan trọng của dataset.
Nhờ đó, mô hình có thể training nhanh hơn, giảm chi phí tính toán và dễ visualize dữ liệu hơn. Một số thuật toán phổ biến trong nhóm này gồm PCA, t-SNE và Autoencoder.
Association Rule Learning
Association Rule Learning là kỹ thuật dùng để tìm mối liên hệ giữa các dữ liệu. Ví dụ nổi tiếng nhất là bài toán “khách mua bánh mì thường mua thêm sữa”. Công nghệ này được ứng dụng rất nhiều trong recommendation system, retail analytics, e-commerce AI và cross-selling.
Amazon là một trong những doanh nghiệp ứng dụng recommendation AI mạnh nhất thế giới. Theo McKinsey, khoảng 35% doanh thu Amazon đến từ recommendation engine.
Self-Supervised Learning
Self-supervised learning là xu hướng rất lớn trong AI hiện đại và thường được xem là phiên bản nâng cao của unsupervised learning. Thay vì cần dữ liệu gắn nhãn từ con người, mô hình sẽ tự tạo “nhãn tạm thời” từ chính dữ liệu để học. Ví dụ, AI có thể dự đoán từ tiếp theo trong câu, dự đoán phần ảnh bị che hoặc dự đoán frame video tiếp theo.
Các mô hình như GPT, BERT hay nhiều foundation model hiện đại đều sử dụng self-supervised learning ở quy mô cực lớn. Theo NVIDIA, phương pháp này giúp giảm đáng kể chi phí labeling dữ liệu trong AI enterprise.

Các thuật toán nổi bật trong Unsupervised Learning
K-Means Clustering
K-Means là thuật toán clustering phổ biến nhất hiện nay. Mô hình sẽ chọn số lượng nhóm K, sau đó xác định tâm cụm và gom dữ liệu vào cụm gần nhất. Điểm mạnh của K-Means nằm ở tốc độ xử lý nhanh, dễ triển khai và hoạt động hiệu quả với dataset lớn.
DBSCAN
DBSCAN nổi bật ở khả năng phát hiện anomaly (dữ liệu bất thường) và xử lý dữ liệu phân bố không đồng đều. Thuật toán này thường được dùng trong fraud detection, phân tích địa lý và network security.
PCA
PCA giúp giảm chiều dữ liệu bằng cách giữ lại các đặc trưng quan trọng nhất. Công nghệ này xuất hiện nhiều trong AI image processing, computer vision, NLP và data visualization.
Autoencoder
Autoencoder là một dạng neural network dùng để học representation của dữ liệu. Công nghệ này thường được ứng dụng trong AI image compression, denoising, feature extraction và generative AI.
Sự khác biệt giữa Supervised và Unsupervised Learning
Supervised Learning (học có giám sát) thường được so sánh với Unsupervised Learning. Điểm khác biệt lớn nhất giữa supervised learning và unsupervised learning nằm ở dữ liệu đầu vào. Supervised learning sử dụng dữ liệu đã gắn nhãn để dự đoán output cụ thể, trong khi unsupervised learning làm việc với dữ liệu chưa gắn nhãn và tập trung vào việc tìm pattern hoặc cấu trúc ẩn.
Supervised learning thường có độ chính xác cao hơn vì mô hình đã biết “đáp án đúng”. Ngược lại, unsupervised learning khó đánh giá hiệu quả hơn nhưng lại có lợi thế lớn khi xử lý lượng dữ liệu khổng lồ mà con người chưa thể phân loại.
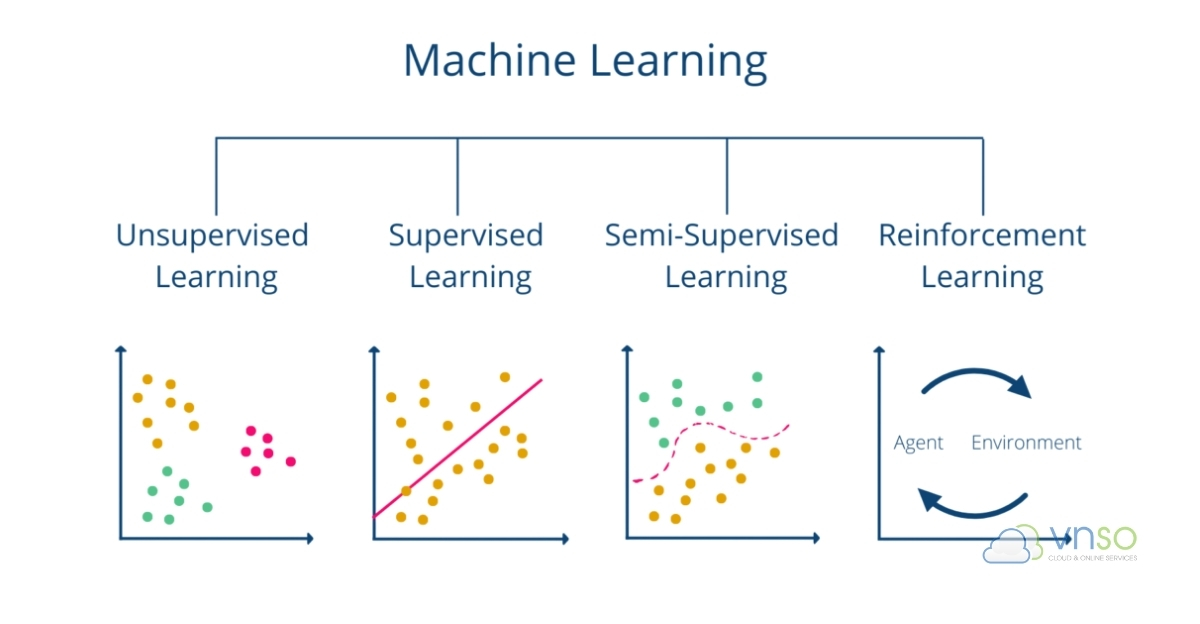
Các loại Machine Learning phổ biến
Ứng dụng và lợi ích thực tế của Unsupervised Learning
Trong lĩnh vực marketing và e-commerce, unsupervised learning thường được dùng để phân tích khách hàng, chạy quảng cáo cá nhân hóa, dự đoán churn rate và tối ưu conversion rate.
Ở các nền tảng như Netflix, TikTok, Spotify hay YouTube, AI recommendation (hệ thống đề xuất bằng AI) kết hợp unsupervised learning với deep learning để phân tích hành vi người dùng và đề xuất nội dung phù hợp. Theo Netflix, hơn 80% nội dung được xem trên nền tảng đến từ hệ thống recommendation.
Trong lĩnh vực tài chính, ngân hàng sử dụng unsupervised learning để phát hiện giao dịch bất thường, nhận diện hành vi gian lận hoặc ngăn chặn account takeover. Điểm mạnh của phương pháp này là có thể phát hiện các pattern gian lận hoàn toàn mới mà chưa từng xuất hiện trước đó.
Ở mảng cybersecurity (an ninh mạng), AI có thể phân tích network traffic, phát hiện truy cập bất thường, detect malware và giám sát hệ thống theo thời gian thực. Theo IBM Cost of a Data Breach Report, chi phí trung bình của một vụ vi phạm dữ liệu toàn cầu năm 2024 đạt khoảng 4,88 triệu USD, vì thế nhiều doanh nghiệp đang tìm và tích hợp nhiều phương pháp khác nhau để tăng cường bảo mật.
Trong computer vision (thị giác máy tính), unsupervised learning còn hỗ trợ image clustering, feature extraction, AI image search và face grouping. Đây cũng là nền tảng quan trọng cho nhiều foundation model hiện đại.
Thách thức lớn nhất của Unsupervised Learning
Dù rất mạnh, unsupervised learning vẫn tồn tại nhiều thách thức. Vì không có “đáp án đúng”, việc đánh giá độ chính xác của mô hình khó hơn supervised learning rất nhiều. Ngoài ra, AI đôi khi có thể phát hiện các pattern không thực sự hữu ích.
Một vấn đề khác là chi phí tính toán. Việc xử lý unlabeled data quy mô lớn yêu cầu GPU mạnh, VRAM cao, memory bandwidth lớn và khả năng xử lý song song mạnh mẽ. Đây là lý do nhiều doanh nghiệp AI hiện nay triển khai hệ thống trên AI Server, Cloud GPU hoặc GPU datacenter chuyên dụng.
>>> Xem thêm Cloud GPU là nền tảng quan trọng trong huấn luyện AI và Machine Learning như thế nào
Unsupervised Learning trong tương lai AI
Nhiều chuyên gia cho rằng tương lai AI sẽ phụ thuộc ngày càng nhiều vào unsupervised learning và self-supervised learning. Nguyên nhân nằm ở việc dữ liệu internet đang tăng quá nhanh, trong khi quá trình labeling thủ công không thể mở rộng tương ứng.
Foundation model hiện đại cần lượng dữ liệu khổng lồ để training, khiến nhu cầu về GPU datacenter, high-performance storage, AI networking và Cloud AI infrastructure ngày càng tăng mạnh.
Kết luận
Unsupervised learning đang trở thành nền tảng quan trọng của AI hiện đại khi lượng dữ liệu toàn cầu tăng với tốc độ quá lớn để con người có thể gắn nhãn thủ công. Khả năng tự tìm pattern, phát hiện xu hướng và phân tích dữ liệu quy mô lớn giúp công nghệ này xuất hiện ngày càng nhiều trong recommendation system, cybersecurity, marketing, finance và generative AI.
Cùng với sự phát triển của foundation model và self-supervised learning, nhu cầu về hạ tầng AI mạnh mẽ như Cloud GPU, AI Server hay GPU datacenter cũng tăng nhanh. VNSO hiện cung cấp dịch vụ Cloud GPU và Server GPU sử dụng các dòng GPU AI hiệu năng cao như NVIDIA A100 và H100, phù hợp cho machine learning (máy học), deep learning (học sâu), AI training và AI inference quy mô lớn.
So với việc đầu tư hạ tầng vật lý chi phí cao, Cloud GPU tại VNSO giúp doanh nghiệp triển khai AI nhanh hơn, dễ mở rộng tài nguyên theo nhu cầu và tối ưu chi phí vận hành cho các dự án AI hiện đại.
>>> Đăng ký thuê ngay Cloud GPU NVIDIA A100 chỉ từ 59k/giờ kèm nhiều ưu đãi!
Điền thông tin của bạn để nhận tư vấn
Các câu hỏi thường gặp về Unsupervised Learning (FAQ)
Unsupervised learning có phù hợp với doanh nghiệp nhỏ không?
Có. Nhiều doanh nghiệp SMEs hiện nay đã sử dụng unsupervised learning để phân tích hành vi khách hàng, tối ưu marketing hoặc phát hiện bất thường trong dữ liệu mà không cần đội ngũ AI quá lớn.
Vì sao dữ liệu càng lớn thì unsupervised learning càng hiệu quả?
Khi dữ liệu tăng lên, AI có nhiều khả năng phát hiện các mối liên hệ và pattern phức tạp hơn. Đây là lý do các hệ thống AI hiện đại thường tận dụng big data để cải thiện chất lượng phân tích.
Unsupervised learning có thay thế supervised learning không?
Không. Hai phương pháp này thường bổ trợ cho nhau. Trong thực tế, nhiều hệ thống AI enterprise kết hợp cả supervised learning và unsupervised learning để tăng độ chính xác và khả năng phân tích dữ liệu.
Unsupervised learning có dùng trong chatbot AI không?
Có. Một số mô hình chatbot hiện đại sử dụng self-supervised learning để học ngôn ngữ từ lượng dữ liệu văn bản cực lớn trước khi fine-tune cho các tác vụ cụ thể.
Vì sao foundation model cần lượng dữ liệu khổng lồ?
Foundation model hiện đại phải học từ hàng tỷ đến hàng nghìn tỷ token dữ liệu để hiểu ngôn ngữ, hình ảnh hoặc hành vi người dùng. Điều này đòi hỏi hạ tầng GPU mạnh và khả năng xử lý dữ liệu quy mô lớn.
Cloud GPU khác gì GPU gaming thông thường?
GPU datacenter như NVIDIA A100 hoặc H100 được tối ưu cho AI training, deep learning và xử lý dữ liệu song song quy mô lớn. Trong khi đó, GPU gaming chủ yếu tập trung vào hiệu suất đồ họa và gaming realtime.
Khi nào doanh nghiệp nên dùng Server GPU riêng thay vì Cloud GPU?
Server GPU riêng phù hợp với doanh nghiệp cần tài nguyên cố định, workload AI chạy liên tục hoặc yêu cầu kiểm soát dữ liệu nội bộ cao hơn. Cloud GPU phù hợp hơn với nhu cầu mở rộng linh hoạt và tối ưu chi phí đầu tư ban đầu.
Vì sao AI enterprise hiện đại cần VRAM lớn?
Các mô hình AI lớn phải lưu trữ lượng tham số và dữ liệu rất lớn trong bộ nhớ GPU. VRAM cao giúp giảm bottleneck khi training hoặc inference các mô hình AI hiện đại.
Thông tin liên hệ
Để tìm hiểu thông tin về các giải pháp AI, Máy chủ, và Điện toán đám mây… Quý khách vui lòng liên hệ chúng tôi theo thông tin dưới đây:
CÔNG TY CỔ PHẦN CÔNG NGHỆ VNSO – SINCE 2015
– Website: https://vnso.vn/
– Fanpage: Facebook | LinkedIn | YouTube | TikTok
– Hotline: 0927 444 222 | Email: info@vnso.vn
– Trụ sở: Lô O số 10, Đường số 15, KDC Miếu Nổi, Phường Gia Định, TP. Hồ Chí Minh
– VPGD Đà Nẵng: 30 Nguyễn Hữu Thọ, Phường Hải Châu, Đà Nẵng
– VPGD Hà Nội: 132 Vũ Phạm Hàm, Phường Yên Hòa, Hà Nội










